GitOps - Demystified
This blog explains GitOps in a simple way, going over what is gitops, the principles of gitops, and why use gitops in the realm of kubernetes.


Having had first-hand experience with both lives before GitOps and after, I can easily say managing Kubernetes applications without GitOps feels like juggling with one hand tied behind your back. Adopting GitOps isn't just about putting an end to the single-source-of-truth conundrum, it opens a whole new plane of automation, enabling you to ship applications faster and more reliably than before. In this blog, the what and the why of GitOps.

What is GitOps? #
As with any new buzzword or term that comes out, a bunch of definitions surface, which causes some haze and confusion around the topic. Simply put, GitOps is a framework in which anything and everything done in your cloud native application is done through git and git alone. It’s considered CD for cloud native applications.
What GitOps is NOT:
-
GitOps is not a single tool. It’s a framework, i.e, a set of practices which if you implement, whatever the tool, then you’d be implementing GitOps.
-
GitOps is not only for kubernetes using the same rationale as the previous point. But because the most widely used GitOps tools are built specifically with kubernetes applications in mind, it might lead people to think that GitOps is exclusive to managing kubernetes applications.
-
GitOps is not synonymous with infrastructure as code. Infrastructure as code is a way to manage your infrastructure. GitOps on the other hand is a way to manage the entire cloud native stack. You can use GitOps to manage your infrastructure as well as the applications deployed on it.
The 4 Principles of GitOps: #
-
The entire system is described declaratively as code.
A declarative system is described as a set of facts as opposed to a set of instructions, i.e., you just state WHAT you want without caring about HOW it’s done. When writing the manifests for our kuberernetes resources, that’s exactly what we do. For example, when creating a deployment, we state the image we want to deploy, the number of replicas, the allocated resources..etc, and we don’t worry about HOW this will be executed.
-
The desired state is versioned in Git.
This principle is the "Git" in GitOps. To implement this principle, any changes introduced to the cluster would be committed to Git. So at any point in time, if you want to know the state of your cluster, you would simply check your git repository, which puts an end to the single source of truth conundrum.
-
Automatically apply approved changes
To enforce the previous principle, we would want to make sure that whatever is committed to the git repository is actually what’s deployed on the cluster, which is where this principle comes in. Having any changes in git automatically applied to the cluster is done by means of software agents that are deployed on the cluster. These agents or controllers constantly monitor any changes added to the repository and apply them to the cluster.
-
Drift Consolidation
At the core of GitOps is this notion of drift consolidation. If at any point in time, for any reason, there is a change or drift between the configuration defined in git and the state of the cluster, the state is reconciled back to the configuration defined in git, which now serves as our single source of truth. I like to think of this as having a control loop for your application deployments.
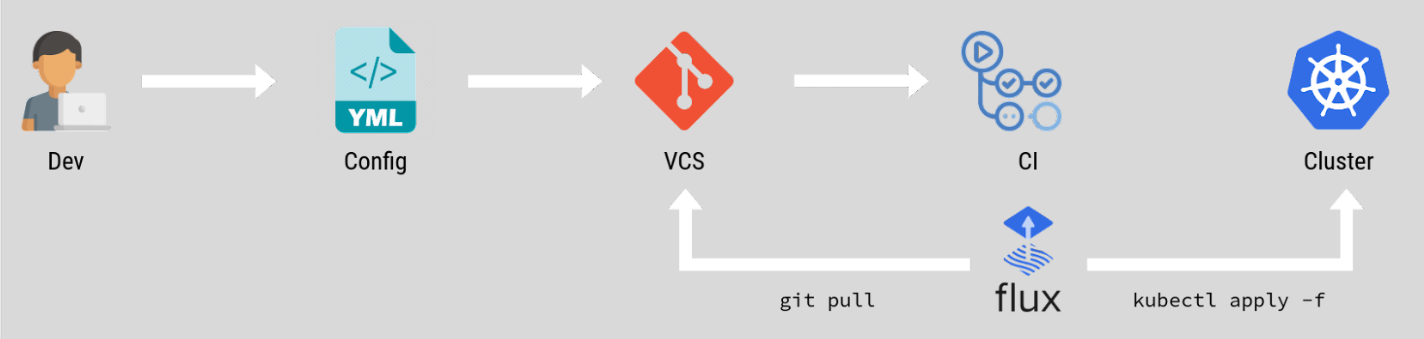
Standard CI/CD vs GitOps #
The standard CI/CD workflow is a push-based model. You push the changes to the manifests on git, then after granting your CI server access to the cluster, you would configure it to run a pipeline applying the new configuration with kubectl or helm.

Up until the third principle, it would seem that a push-based deployment model would be implementing GitOps, after all, its source is Git and the CD is triggered through git, right? But let's clarify the difference.
GitOps is pull-based, i.e., the cluster state is updated by pulling the desired state from the repository and then applying it. The agent running on the cluster does that periodically, not just on push. So, the glaring difference between the push-based deployment model and GitOps is in having that control loop that's always running, observing and syncing the state of the cluster with the state of the repository all the time.
Why GitOps? #
It's important to weigh out the benefits and drawbacks of any adopted framework before riding the wave and then wondering what has ever got you in that mess in the first place. So by now, you might be wondering, why do we even need GitOps? CI/CD did the job, Kubernetes is complicated enough without introducing a new framework. Well, that would be very valid if we live in an ideal world, but if I've learned anything during my time working with Kubernetes, it's that Murphy's law is real.
"Anything that can go wrong will go wrong." - Murphy's Law.
A namespace is bound to go mysteriously missing, or someone is going to modify something on the cluster and forget to commit it to git, mistakes are inevitable, and it's good to be proactive.

So here are just some of the benefits of GitOps:
-
Easier and quicker error handling and recovery.
Imagine you're playing around in the cluster - as we all do - and you accidentally modify or completely remove a resource without noticing, GitOps will save your life. The software agent will pick up on the difference between the desired state of the cluster defined in the git repository and the actual state of the cluster and will automatically reconcile the state of the cluster to match the desired state and undo whatever changes you didn't intend to introduce.
Now imagine another scenario, where the resource you apply introduces an unintended bug. If you're using GitOps, you'd be pushing changes simply by pushing your commits, so reverting changes would be as easy as a simple
git revert.
Beyond recovering from disasters, a lot of perks come with adopting GitOps
-
Deploy faster and more often.
GitOps really delivers on the speed of application delivery. Once the new feature is developed and tested, there is no "post merge" step to deliver, once you merge your latest changes and push those commits to the branch being synced to the cluster, changes are automatically pushed and applied.
-
Self-documenting deployments and shared knowledge in the team.
Another cool feature that we end up with when using GitOps is that the state of the cluster is directly reflected by the git repositories. So the entire development team can easily find out exactly what is deployed at any point in time just by checking the repo. Developers no longer have to access the cluster to find out which version of a certain helm chart is deployed or if their latest release has been deployed yet or not. Additionally
-
Easier credential management.
Because application delivery is now pull-based, we no longer have to give our CI server full access to the cluster to apply changes as we did before GitOps. And by extension, the same applies to giving cluster access to developers. Creating, updating or deleting resources can now be managed entirely through git.
Now that you know some of the benefits of GitOps, you can start evaluating whether it's for you or not. If you're just one or two developers working on a non-critical test cluster, you may not need GitOps, but you may start considering implementing it when the team and/or applications start to scale.

Follow Kubesimplify on Hashnode, Twitter and LinkedIn. Join our Discord server to learn with us.
Get new posts in your inbox.
Spotted a typo or want to improve this post? Edit on GitHub →