StatefulSets
Before getting into what Statefulsets are, let us first talk about what Stateful and stateless applications are. Stateful apps keep track of the…


On this page (3)
Before getting into what Statefulsets are, let us first talk about what Stateful and stateless applications are.
Stateful and Stateless applications #
Stateful apps keep track of the session(state) details of the previous transactions that happened and they will behave differently based on the previous state of the application.
While the stateless applications only rely on the clients to have some session data but the server itself doesn't store any session data.
Note: The term "State" means multiple things in multiple contexts. In this particular context, it mostly refers to the session details or some authorization tokens.
To understand more, let's take an example of a banking application that is built in both stateful and stateless architecture.
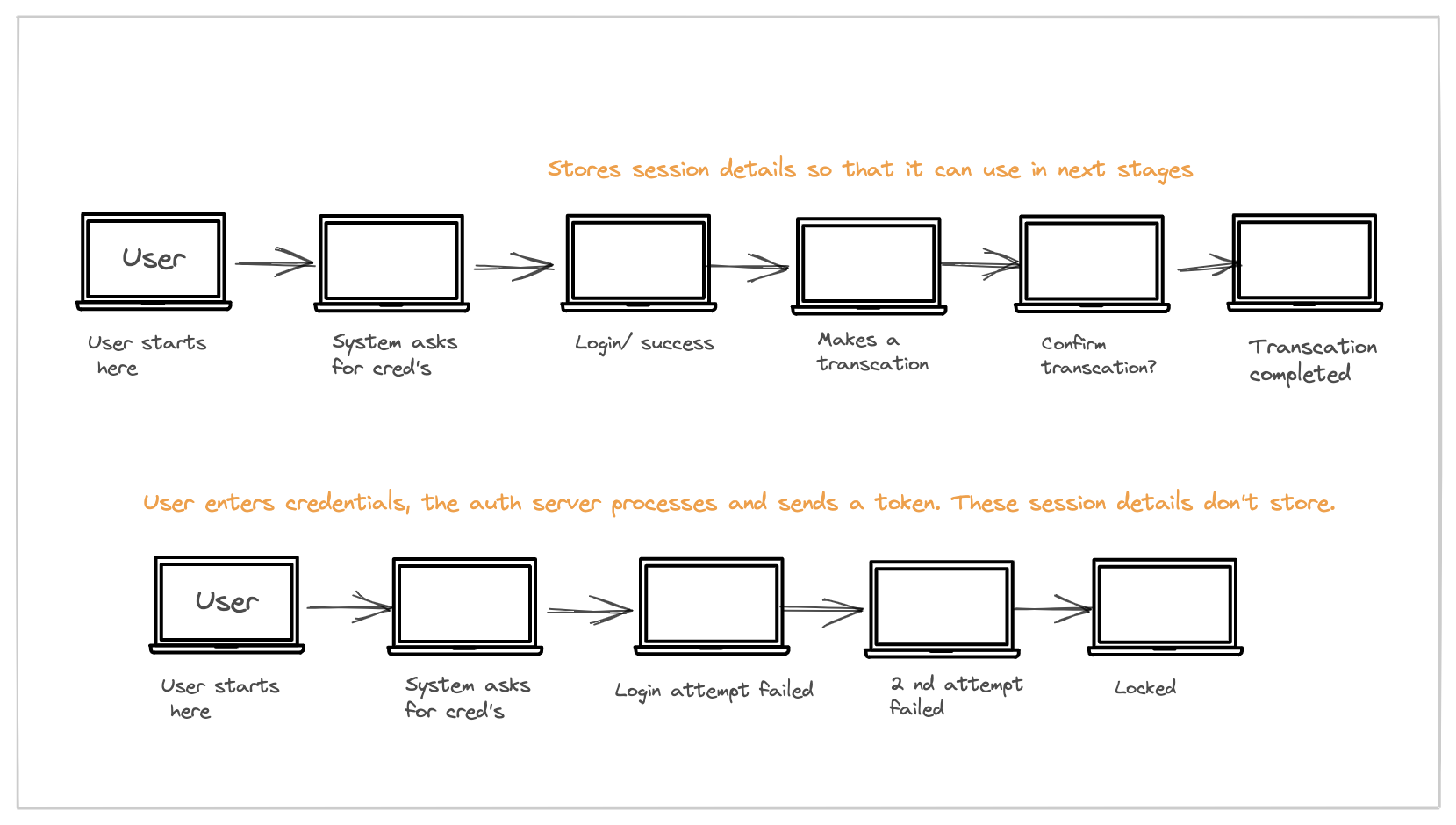
Assume that you want to make a transaction of $1000 from your bank account using the application. What are the steps that are involved?
-
User has to log in using their credentials.
-
Choose the transaction and enter the amount to transfer.
-
Confirmation of the transaction.
-
The transaction is marked as complete.
Let us perform all the steps mentioned above in both stateful and stateless architectures.
In a stateful way, the user enters his credentials, the server verifies the credentials in the auth server, and authentication is successful. As the application is built in stateful architecture, the state is stored in the server.
Then the user is prompted with a transaction page which might or might not be on the same node(server) as the auth server, but as the state(auth details) are already stored in the server the request will be processed without any hassle. Same for the confirmation stage, it will get auth details from the state store. Our user performed his transaction successfully.
In a stateless way, the server verifies the credentials in the auth server, and authentication is successful. As the application is built in stateless architecture, the state is not stored in the server.
But when the user prompts to the transaction page which might not be the same server as auth server. As auth details (state) aren’t stored in the server, the user fails to authenticate. The login screen appears again, this will continue to repeat which results in difficulty to make a transaction.
Note: The operations are simplified and can't be compared with real-world cases.
I hope now we have some idea about what stateful and stateless applications are. Let’s see what StatefulSets are, how they are different from Deployments, and how to create one.
StatefulSet #
"StatefulSet is a Kubernetes API object that is used to manage stateful applications"
Coming to deploying applications in Kubernetes, we already have Deployments which is very useful. Then why we would need StatefulSets? What is the added advantage that we get from using StatefulSets?
Issues with Deployments
Yes, deployments are very useful to deploy applications, they provide replicas, and make rollbacks and updates easy. But deploying Stateful applications using deployments comes with some issues as follows.
-
Pods created with Deployments don’t provide Persistent identity
-
All pods created with Deployment share the PV
-
Scaling up and Scaling down in deployment is instantaneous
For better understanding let's create a sample deployment and discuss the issue mentioned above.
In this example, I’m deploying a Redis image with 2 replicas with PV attached to it. Create the Deployment using kubectl apply -f deployment.yml.
You can find the manifests here
- Pods don’t have a persistent identity
By default, the pods that are created with deployment names are as follows: Deployment name- [random hash number]. This inconsistent naming convention makes the database connections unreliable which needs to be reliable in the case of Stateful applications.

- All Pods share the same PV
All the replicas that are created with Deployment share the same Persistent Volume( if provided). This makes the whole application prone to downtime considering the cases where the PV can crash. You can see which pod has attached to which PV using the following command.
kubectl get po -o json --all-namespaces | jq -j '.items[] | "\(.metadata.namespace), \(.metadata.name), \(.spec.volumes[].persistentVolumeClaim.claimName)\n"' | grep -v null
- Scaling up and Scaling down
In Deployments, the Scaling up and Scaling down are instantaneous. This means all the pods are scheduled at the same time and also during the Scale down all the pods terminate at the same time.
-
Scaling up the deployment using
kubectl scale deployment/redis-cluster --replicas=10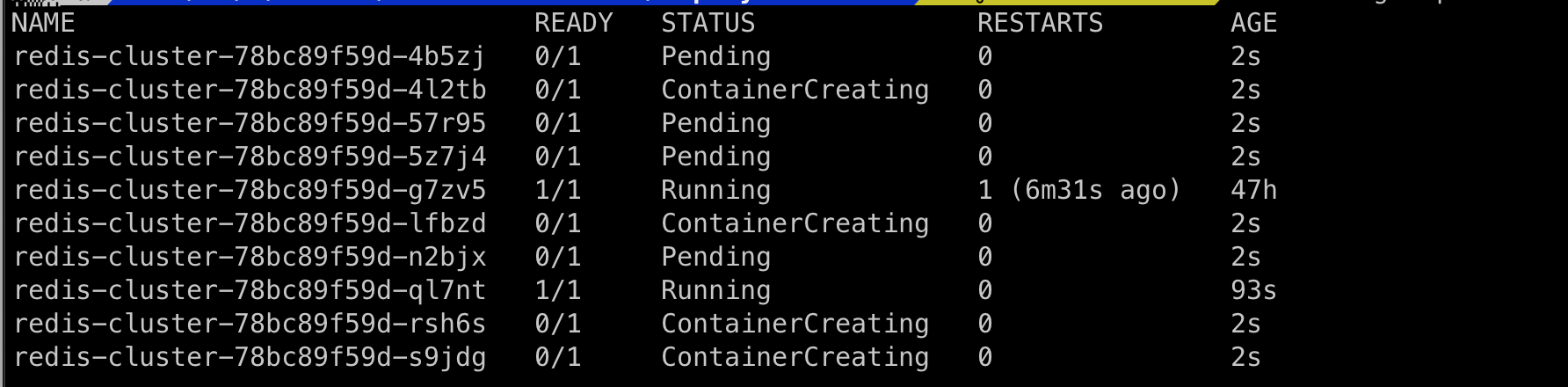
-
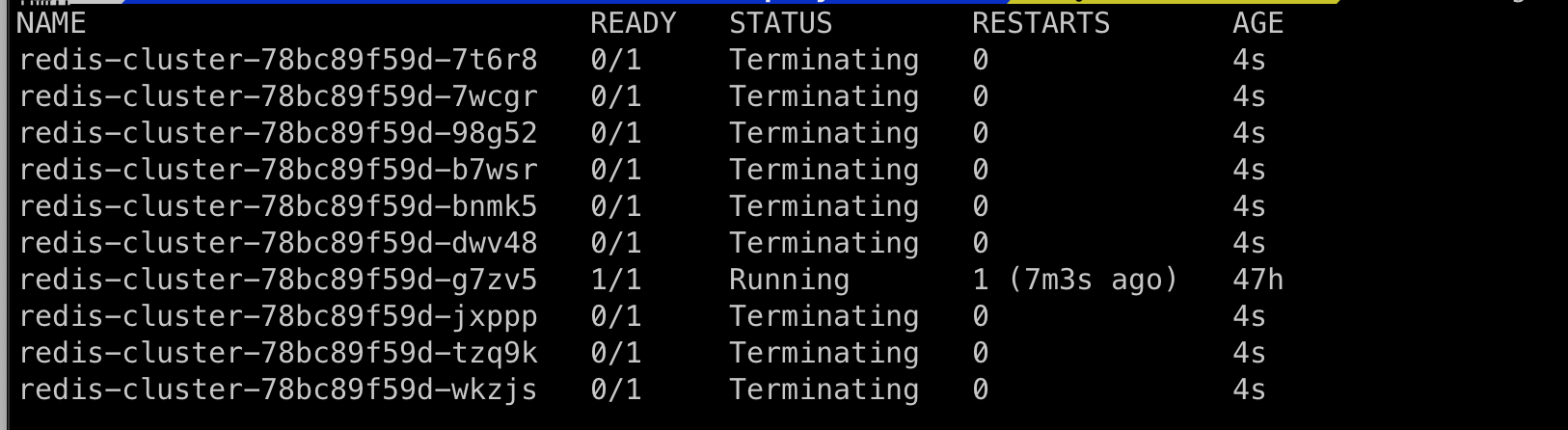
Now try to scale down the deployment using
kubectl scale deployment/redis-cluster --replicas=1 -
As you can see this instant scaling up/scaling down can cause an abrupt change in the stateful application and can cause downtime.
StatefulSets #
Let’s see how statefulset deploys an application and whether will it solve the issues that we got from Deployments or not.
A StatefulSets provides a persistent identity to the pods that they create and manage. The StatefulSets are mostly used for deploying Stateful applications where we require a unique network identifier or Storage.
StatefulSets also guarantees the ordering of the pod deployment and its scaling. StatefulSets are very helpful while deploying applications where you need database clustering ( in which you need to know the hostname of each server).
StatefulSet Yaml Manifest:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: redis-cluster
spec:
serviceName: redis-cluster
replicas: 2
selector:
matchLabels:
app: redis-cluster
template:
metadata:
labels:
app: redis-cluster
spec:
containers:
- name: redis
image: redis:5.0.1-alpine
ports:
- containerPort: 6379
name: client
- containerPort: 16379
name: gossip
command: ["/conf/update-node.sh", "redis-server", "/conf/redis.conf"]
env:
- name: POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
volumeMounts:
- name: conf
mountPath: /conf
readOnly: false
- name: data
mountPath: /data
readOnly: false
volumes:
- name: conf
configMap:
name: redis-cluster
defaultMode: 0755
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 50Mi
---
apiVersion: v1
kind: Service
metadata:
name: redis-cluster
spec:
clusterIP: None
ports:
- port: 6379
targetPort: 6379
name: client
- port: 16379
targetPort: 16379
name: gossip
selector:
app: redis-clusterStatefulSet requires a Headless Service in order to route the traffic to pods and to be accessed.
- Pods and their identity
Pods that are created using StatefulSet are named as [Statefulset-name- (ordinal number)]. The ordinal number ranges from 0 to N and the number defines the order of creation.
This Standard naming convention provides a persistent identity to the pods and makes them reliable for use in database connections.

- Pods have separate PV
Every Pod that is created with Statefulset gets its own Volume. You can verify this using the following command.
kubectl get po -o json --all-namespaces | jq -j '.items[] | "(.metadata.namespace), (.metadata.name), (.spec.volumes[].persistentVolumeClaim.claimName)\n"' | grep -v null
- Scaling up and Scaling Down
Stateful sets handle the Scaling very gracefully, It will ensure that the second Pod will not be created unless the first pod is up and running. (0 to N)
In the same manner, during the Scale down, the Pod with the highest ordinal number terminates first and the second highest pod only starts terminating after that. (N to 0)
-
Let's scale up our stateful set from 5 to 10 pods, you can do that by using
kubectl scale sts/redis-cluster --replicas=10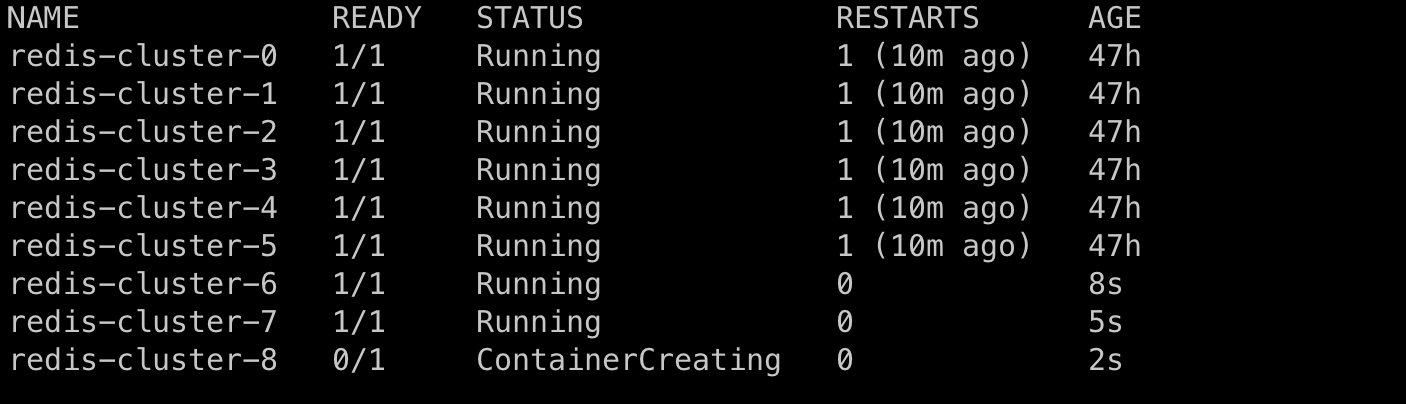
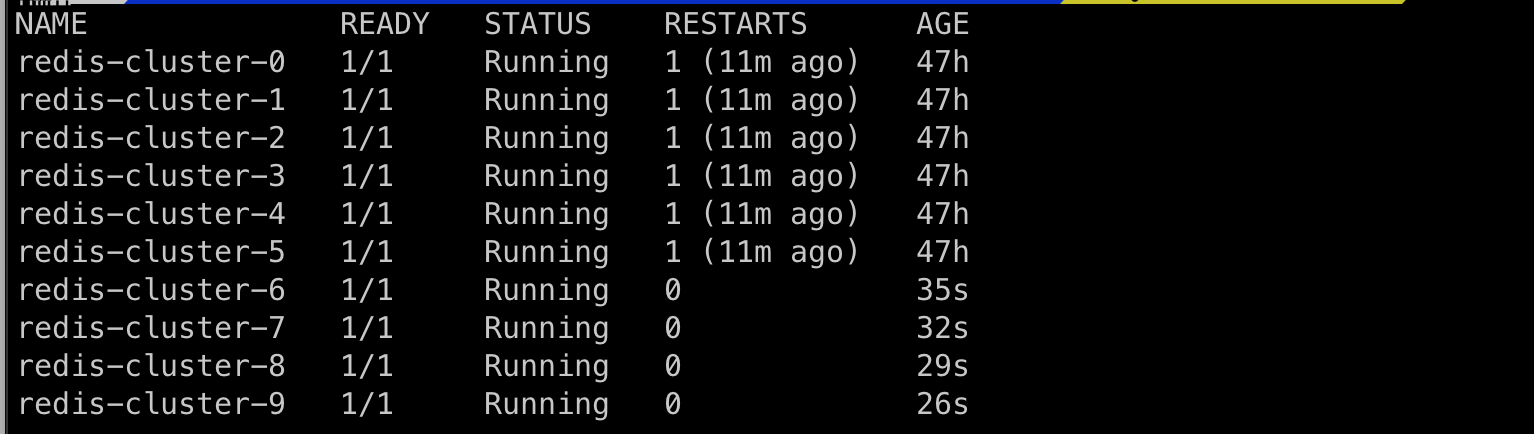
- As you can observe in the above pictures, the statefulsets scale the pods one by one, and the scaling down can be achieved by using
kubectl scale sts/redis-cluster --replicas=1.
Note: StatefulSets is a great option to run your Stateful applications but by default, Kubernetes doesn’t enable the database clustering for your database. Clustering is necessary for some databases in order to ensure all the volumes (databases) maintain the replica of the data.
Follow Kubesimplify on Hashnode, Twitter, Instagramd and Linkedin. Join our Discord server to learn with us.
Hey there 👋 I am Srinivas Karnati, a DevOps Engineer. I am interested in Cloud Native, Open source, and would love to help folks in their journey.
Get new posts in your inbox.
Spotted a typo or want to improve this post? Edit on GitHub →