What Claude Code's Leaked Source Actually Teaches Us About Building AI Agents
512K lines of TypeScript, verified against actual source. The engineering patterns in Claude Code's leaked codebase that most coverage got wrong.


On this page (7)
Let me start with the honest version of what happened.
Yesterday, Anthropic accidentally published a 59.8 MB source map file inside version 2.1.88 of their @anthropic-ai/claude-code npm package. The build pipeline was configured to generate source maps, and the packaging step — whether it was a missing .npmignore rule or a misconfigured files field in package.json — failed to exclude them. One packaging oversight, and ~512,000 lines of TypeScript source were public. Anthropic's DMCA notice eventually took down over 8,100 GitHub repositories. A clean-room rewrite called claw-code hit 50,000 stars in about two hours and now about 100k+.
Within last 24 hours, the internet was flooded with hot takes. Architecture diagrams. The virtual pet system. Thread after thread of "I read the entire codebase and here's what I found." Sites like ccunpacked.dev did genuinely good visual walkthroughs of the high-level structure.
But let's be real — nobody read 512,000 lines of TypeScript. I certainly didn't, and I'm skeptical of anyone who claims they did. What I did do was feed the source into Claude, systematically analyzed the key modules, cross-referenced what I found against public documentation and other analyses, and verified the claims I'm about to make against the actual code. If you've read other "I analyzed the leak" posts, they probably all used a similar workflow. The difference I'm going for here is honesty about the process.
The Core Loop Is a State Machine, and That's the Whole Point #
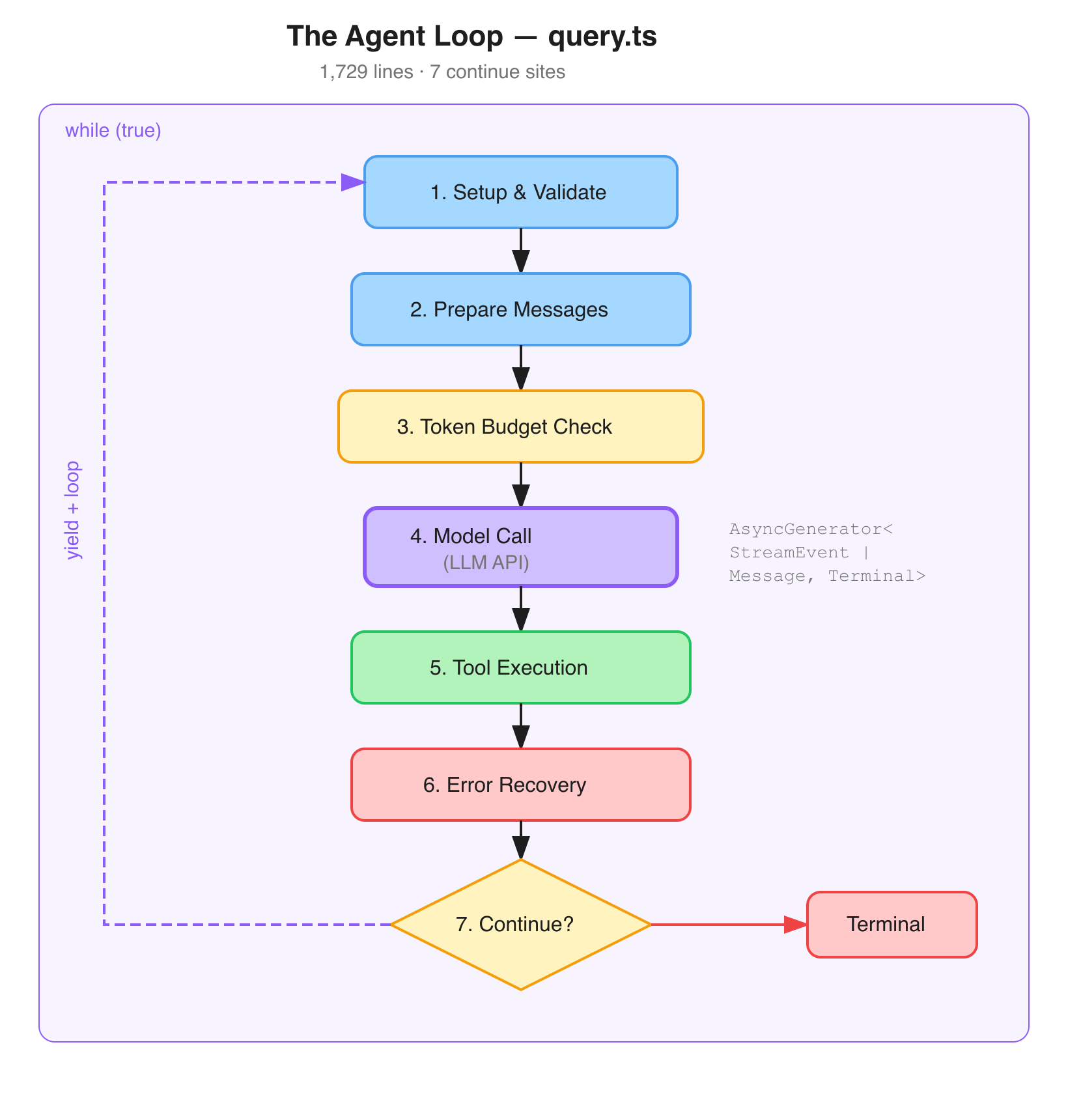
The agent loop lives in query.ts. It's exactly 1,729 lines (I checked), structured as an async generator function called queryLoop wrapping a while(true) loop. The code itself, in an internal comment, references "7 continue sites" — seven distinct points where the loop yields control and decides what to do next.
The actual function signature:
async function* queryLoop(
params: QueryParams,
consumedCommandUuids: string[],
): AsyncGenerator<
StreamEvent | RequestStartEvent | Message | TombstoneMessage | ToolUseSummaryMessage,
Terminal
>Why does this matter? Because most agent frameworks treat the LLM call as the center of gravity. Send a prompt, get a response, run a tool, repeat. That works fine for demos. It falls apart the moment you need to pause a session, resume it later, serialize state, handle errors mid-turn, or compose multiple agents together.
The generator pattern makes every loop iteration an explicit state transition. You can yield control at each of the seven points without losing state. You can test individual stages. You can add compaction, permission checks, or budget tracking as stages rather than side effects bolted onto a callback chain.
If you're building an agent and your core loop is a simple while with await model.chat() in the middle, this is the pattern to study.
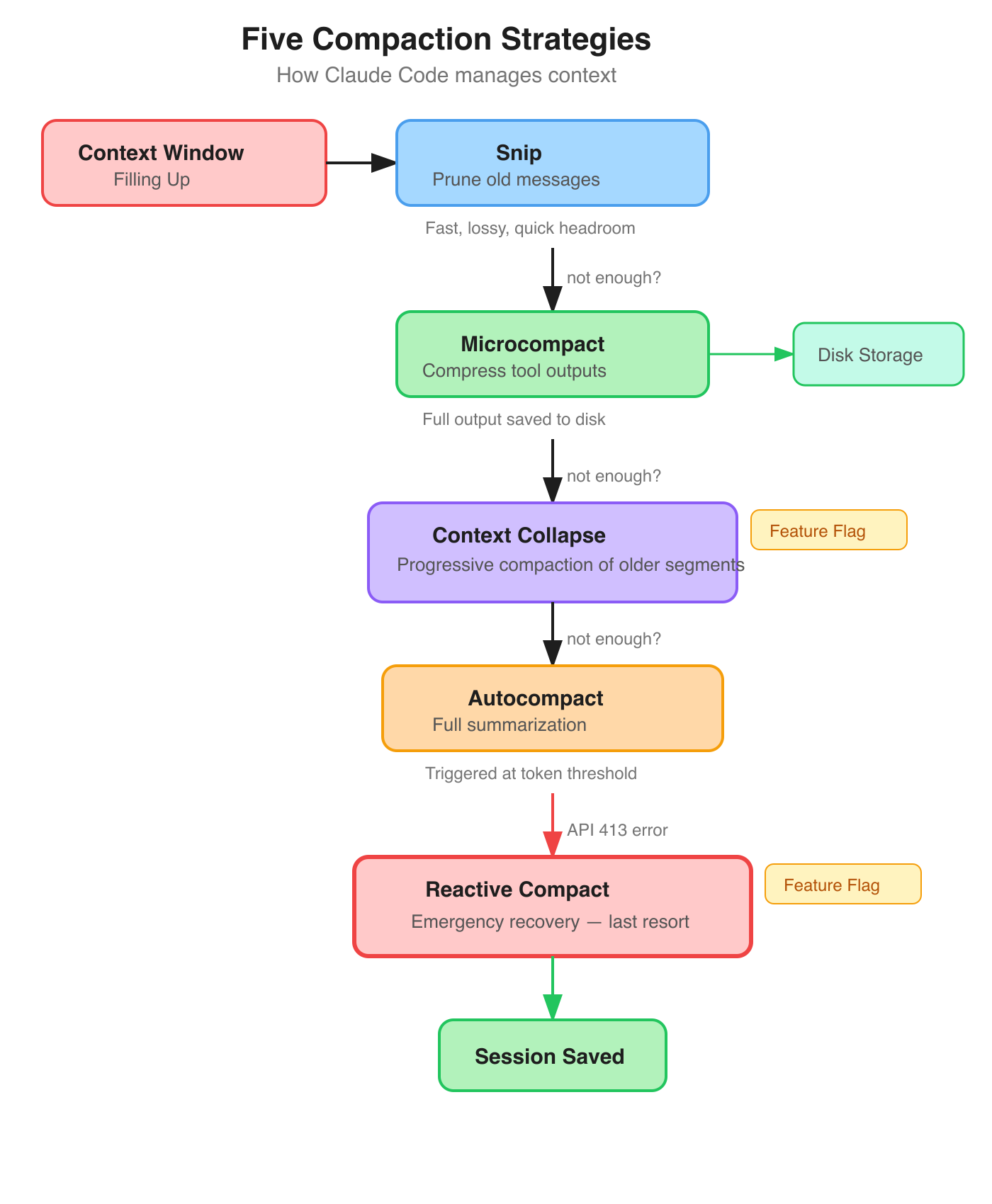
Five Compaction Strategies (Not a Neat Stack) #
Every long-running agent eventually fills its context window. Most frameworks handle this by truncating old messages. Claude Code has five distinct strategies — though I want to be clear, these aren't a clean "Layer 1 through 5" hierarchy like some other posts have described. They're composable strategies that kick in under different conditions:
Snip prunes older messages for quick headroom. Fast and lossy.
Microcompact targets tool outputs specifically. A 5,000-line file read gets saved to disk; the model sees a summary with a reference. Two implementations handle this: microCompact.ts and apiMicrocompact.ts. This alone is a big deal — a single uncompressed tool output can eat half your context window.
Context Collapse progressively compresses older conversation segments while keeping recent context sharp. It's still behind a CONTEXT_COLLAPSE feature flag, with dedicated persistence types (ContextCollapseCommitEntry, ContextCollapseSnapshotEntry) to survive session restarts. Not yet fully shipped.
Autocompact is full-conversation summarization at configurable token thresholds. Replaces older history with a summary.
Reactive Compact is the emergency brake — behind the REACTIVE_COMPACT feature flag. When the API returns a 413 (payload too large), this aggressively compacts everything so your session doesn't die. Without this, one bad tool output would brick the conversation.
Now, I've seen posts claiming "no other framework has this." That was arguably true in 2025, but it's not true now. Microsoft's Agent Framework has composable multi-strategy compaction pipelines. LangChain Deep Agents (shipped March 15, 2026) does filesystem offloading plus multi-frequency summarization. Google ADK has sliding window with summarization.
What sets Claude Code apart isn't that it has compaction — it's the granularity. Five strategies, two of them still being iterated on behind feature flags. That reflects the kind of edge cases you only discover at scale.
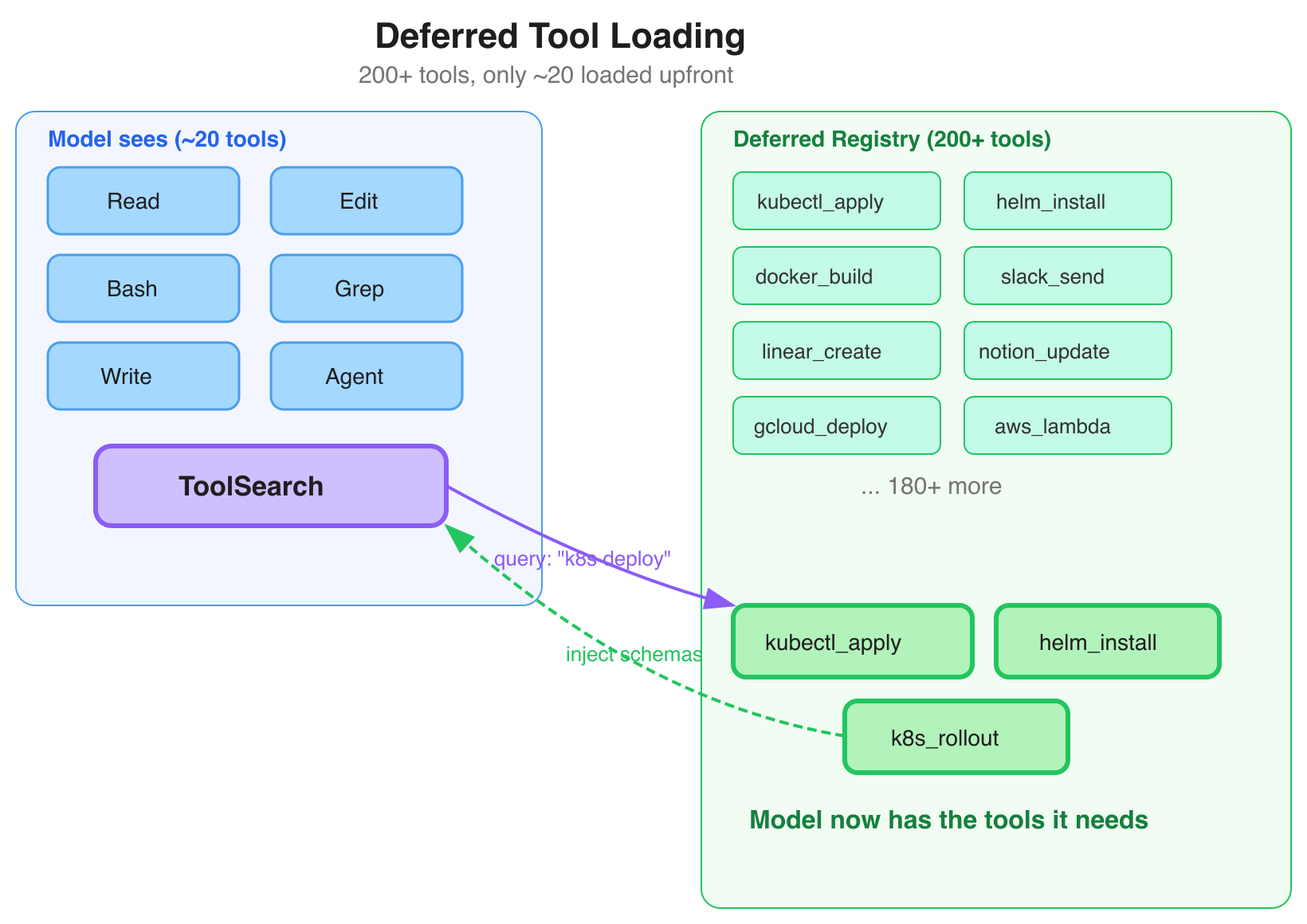
Deferred Tool Loading #
This is probably the most practical pattern in the codebase for anyone building agents.
When you connect MCP servers, you might have 200+ tools available. Sending all those schemas on every API call wastes thousands of tokens. Claude Code's solution: mark tools with defer_loading: true. The model doesn't see them. Instead, it has a single meta-tool called ToolSearch (the internal class is ToolSearchTool, but the model-facing name is ToolSearch — defined as TOOL_SEARCH_TOOL_NAME = 'ToolSearch' in the constants). When the model needs a capability, it calls ToolSearch with a query:
User: "Deploy this to my Kubernetes cluster"
Model calls ToolSearch("kubernetes deploy")
-> System fuzzy-matches deferred tool descriptions
-> Injects matching schemas into the conversation
Model now has the tools it needs.The model goes from ~20 core tools to access to hundreds, without the upfront token cost.
This pattern has spread. The OpenAI Agents SDK now has deferLoading: true with tool search (requires GPT-5.4+). ZeroClaw implements nearly identical deferred loading. CrewAI 1.10.2a1 (March 2026) added dynamic tool injection via Anthropic's tool search API.
But there's still no framework-agnostic library for this. The core is straightforward — fuzzy matching over tool descriptions, schema injection on demand, MCP compatibility. If someone built this as a standalone package, it'd be useful immediately.
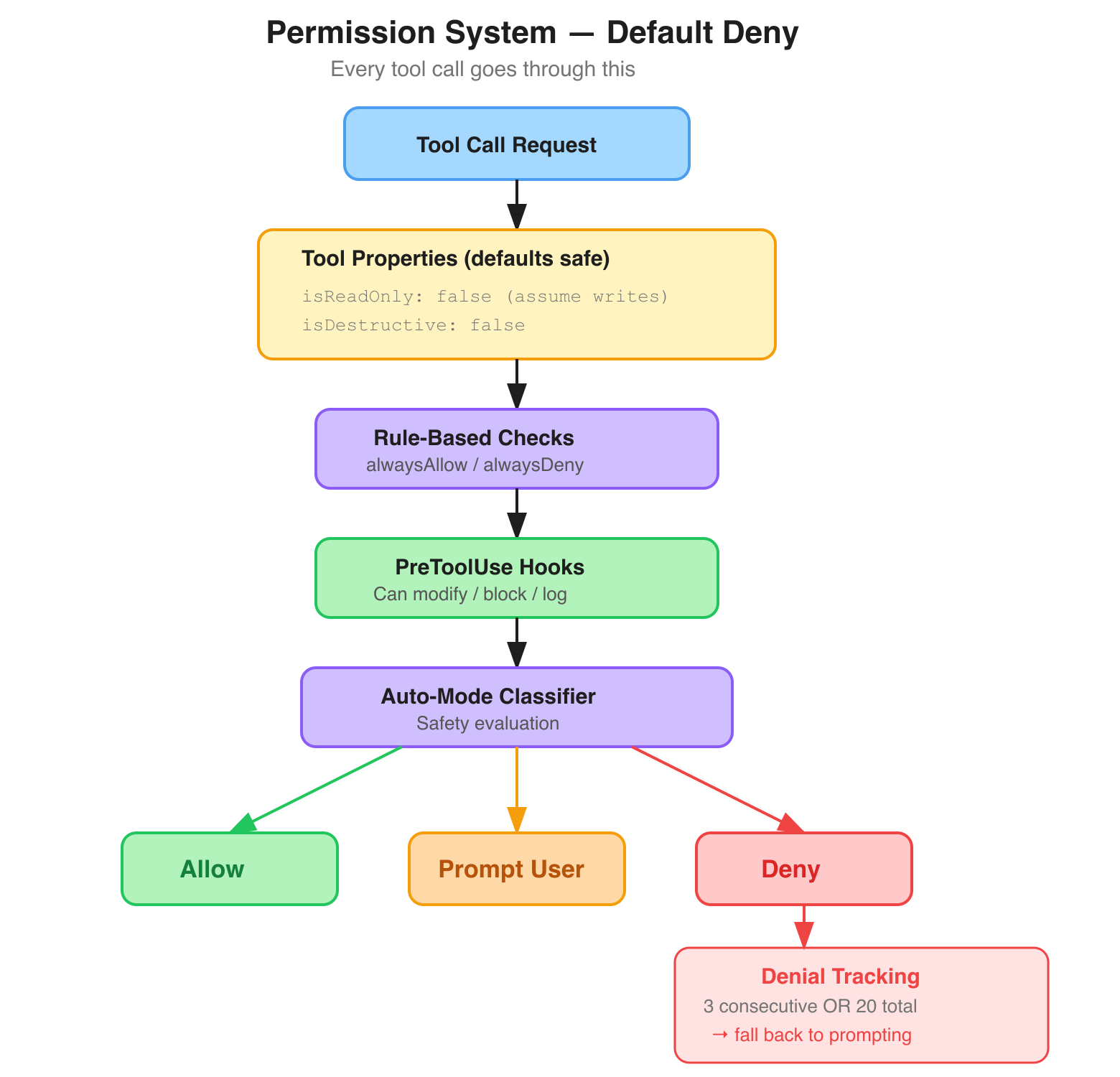
Default-Deny Permissions With a Graceful Fallback #
Claude Code's permission system is built on default-deny. Every tool has two permission-relevant properties defined in Tool.ts:
-
isReadOnly— defaults tofalse(assume the tool writes) -
isDestructive— defaults tofalse
Tools must explicitly declare their risk profile. The permission system then layers rule-based checks (alwaysAllow/alwaysDeny rules), pre-tool-use hooks (which can modify input, block execution, or log), and an auto-mode safety classifier.
The part I found most interesting is the denial tracking in denialTracking.ts — just 46 lines:
3 consecutive denials → shouldFallbackToPrompting() returns true
20 total denials in a session → same resultIf the user keeps saying "no," the system stops running in auto-mode and starts asking for explicit permission on every action. Most agent frameworks either keep retrying or hard-stop. Claude Code's approach gracefully degrades: "You're uncomfortable with what I'm doing, so I'll check before each step."
Small file, big principle.
The Cost Engineering #
These are the details that only matter at Anthropic's scale, but they're instructive:
Sticky-on latches. When a feature flag activates during a session, it stays on for the rest of that session. Flipping it back would change the system prompt, which busts the prompt cache. The promptCacheBreakDetection.ts file tracks 14 distinct state fields that can invalidate the cache — system prompt hash, tool schema hashes, model changes, beta headers, effort values, and more. Sticky latches prevent unnecessary cache invalidation from mode toggles.
Tool result persistence. Large outputs get written to disk; the model sees a preview. This isn't just context management — it keeps the cache prefix stable.
Schema stability. Tool schemas assembled once at session start, held stable throughout. MCP tools can come and go, but the core schema block doesn't change.
At scale, these optimizations compound significantly.
What I Actually Took Away From This #
I'm not going to pretend the leak is a startup idea list or that I discovered things nobody else saw. But analyzing the code did crystallize a few things:
Context management is harder than it looks. Five strategies, two still behind feature flags, a dedicated promptCacheBreakDetection.ts tracking 14 vectors. This is not a solved problem, even for Anthropic.
Deferred tool loading is becoming table stakes. Claude Code, OpenAI, ZeroClaw, CrewAI — multiple teams independently arrived at the same pattern. If you're building an agent with more than ~20 tools and you're not doing this, you're wasting tokens.
Permission design matters more than permission features. The denial tracking system is 46 lines. The principle it encodes — "degrade gracefully when the user loses trust" — is more important than any specific implementation detail.
The real work is in the orchestration. The model call is one stage out of seven in the main loop. Everything else — state management, compaction, tool loading, permissions, cost optimization — is where the engineering actually lives.
Being Honest About the Process #
Every blog you've read about this leak was written with AI assistance. This one included. I used Claude to analyze the source modules, identify patterns, and draft the initial structure. I then fact-checked every claim — cross-referencing the actual source code, public documentation, news coverage, and other technical analyses. Where I found errors in my initial draft (and there were several), I corrected them.
The value isn't in pretending I manually read half a million lines of code. It's in doing the verification work to make sure what I'm telling you is actually true. In a sea of AI-generated analysis of AI-generated code, accuracy is the differentiator.
If you spot something wrong, tell me — I'd rather correct it than let it stand.
I write about cloud-native, AI engineering, and the infrastructure that makes modern software work. Find me on Twitter or LinkedIn.
Saiyam is working as Head of DevRel at vCluster Labs. He is the founder of Kubesimplify, focusing on simplifying cloud-native & AI infrastructure. He is KubeCon Co-chair and has worked on many facets of Kubernetes, including machine learning platforms, scaling, multi-cloud, & managed Kubernetes services. When not coding, Saiyam contributes to the community by writing blogs and organizing local meetups for Kubernetes and CNCF. He is also a CNCF TAG OpsRes Chair & can be reached on Twitter @saiyampathak.
Get new posts in your inbox.
Spotted a typo or want to improve this post? Edit on GitHub →