NVCF Is Now Open Source: Inside NVIDIA's GPU Function Platform
NVIDIA just open-sourced the full NVCF platform under Apache 2.0. Not a thin SDK, not a client library. The actual control plane, invocation plane,…


On this page (9)
NVIDIA just open-sourced the full NVCF platform under Apache 2.0. Not a thin SDK, not a client library. The actual control plane, invocation plane, compute plane, CLIs, Helm charts, and database migrations, all in one monorepo at github.com/nvidia/nvcf.
NVCF powers infrastructure behind services like build.nvidia.com and NVIDIA-hosted inference workflows across GPU cloud providers and DGX Cloud environments.. Now you can run the whole thing yourself and read every line that makes it work.
Let’s break down how the platform actually works.
What NVCF Actually Is #
NVCF stands for NVIDIA Cloud Functions. The original managed service let you register a Docker container or Helm chart, specify a GPU type, and NVIDIA handled everything: routing, queueing, autoscaling, multi-tenant isolation. GPU cloud partners like CoreWeave ran the NVIDIA Cluster Agent on their Kubernetes clusters so their GPUs could serve functions while NVIDIA owned the control plane.
The April 2026 Apache 2.0 release publishes that control plane. The previous repos (NVIDIA/nvidia-cloud-functions, NVIDIA/nvcf-go) are now archived. This monorepo is the one place everything lives.
One honest caveat: the control plane images are currently distributed via NVIDIA's NGC registry under the nvcf-onprem org. You need NGC access to deploy the full stack today. The source code is all Apache 2.0 and inspectable, but the deployable bundle still goes through NGC while issue #12 (full OSS build) is open. I opened issue #14 asking for a community contributor path.
Three-Plane Architecture #
The entire platform is built around three independently scalable planes connected through NATS JetStream.
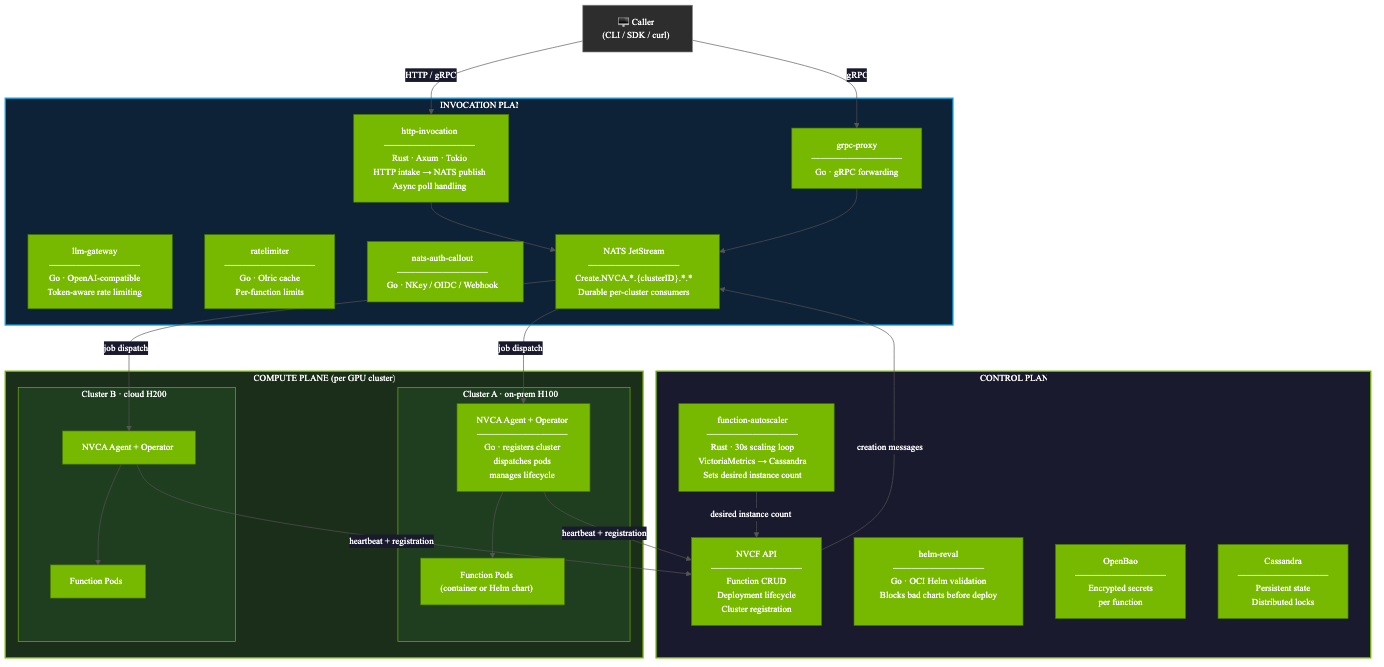
Control Plane runs on a dedicated Kubernetes cluster and owns function lifecycle, autoscaling decisions, and secrets management. Key services:
-
function-autoscaler(Rust): runs a 30-second scaling loop, reads utilization from VictoriaMetrics, writes decisions to Cassandra, calls the NVCF API to set desired instance counts -
helm-reval(Go): validates OCI-referenced Helm charts before the compute plane deploys them -
OpenBao (Apache 2.0 Vault fork): all function secrets encrypted at rest, injected at runtime via the ess-agent sidecar
-
Cassandra: persistent state and distributed locks for the autoscaler
Invocation Plane sits between every caller and every GPU worker. Nothing bypasses it:
-
http-invocation(Rust / Axum): receives HTTP/gRPC requests, publishes to NATS JetStream, handles async polling -
llm-gateway(Go): OpenAI-compatible API with token-aware rate limiting via embedded Olric cache -
grpc-proxy(Go): forwards gRPC calls to function instances -
ratelimiter(Go): per-function rate limiting using Olric distributed cache -
nats-auth-callout(Go): NATS authentication with NKey, OIDC, and webhook strategies
Compute Plane is one NVCA (NVIDIA Cluster Agent) operator per GPU cluster. NVCA registers the cluster with the control plane, consumes NATS messages, and manages pod lifecycle.
How a Single Request Flows #
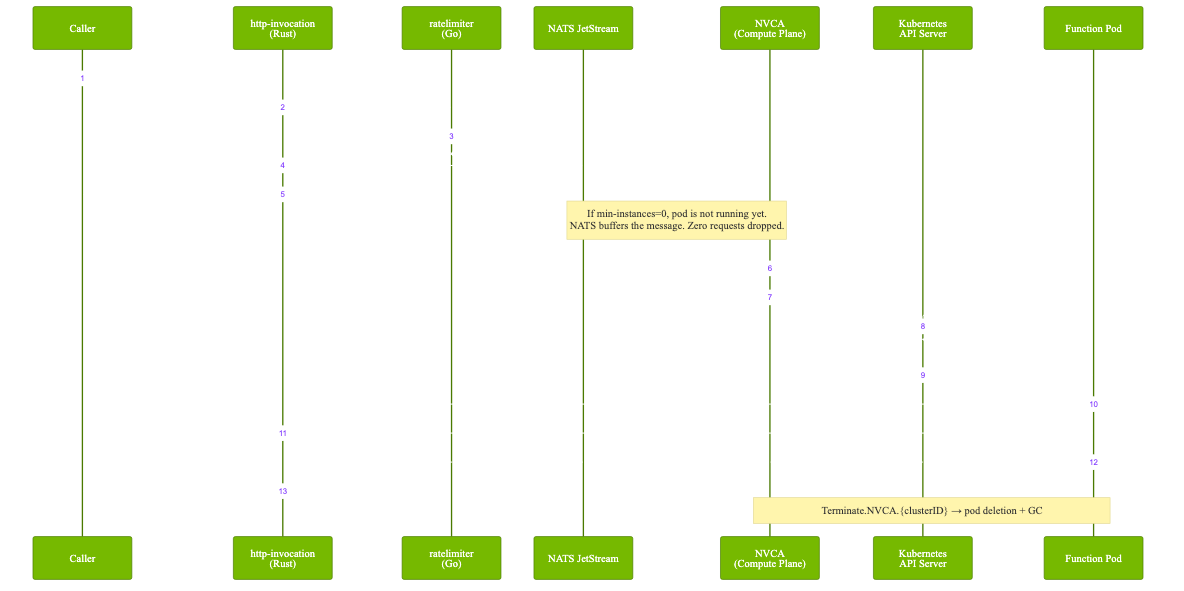
Every invocation follows this path verified from the source code:
-
Caller posts to
POST /v2/nvcf/pexec/functions/{id} -
http-invocationchecks rate viaratelimitergRPC -
Request published to NATS stream:
Create.NVCA.*.{clusterID}.*.*(fromnvca/pkg/queue/nats/client.go) -
NVCA queue manager consumes the message
-
ICMSRequestKubernetes CR created (deduplication by NATS sequence) -
MiniService controller reconciles: creates Pod or applies Helm chart
-
Function pod connects back via
WorkerServicegRPC:ConnectOnce -
Response returns to the caller
-
On completion:
Terminate.NVCA.{clusterID}triggers pod deletion and GC
Scale-to-Zero: The NATS Buffer Approach #
This is the most important architectural decision in the whole codebase, and it is fundamentally different from how Knative handles scale-to-zero.
With Knative, requests can experience timeout or retry pressure during long scale-up events, especially for GPU workloads with heavy cold starts. That model works well for lightweight stateless HTTP services that initialize quickly. GPU inference workloads are different. Loading large models into VRAM can take tens of seconds or even minutes, making durable request buffering much more important.
NVCF uses NATS JetStream as a durable request buffer:
-
Autoscaler drives desired instance count to 0. No pods running.
-
New request arrives. Published to NATS JetStream. Stream persists it durably.
-
Autoscaler detects queue depth > 0. Sets desired instances to 1+.
-
NVCA receives creation message, launches pod.
-
Pod connects via WorkerService gRPC, pulls the buffered message.
-
Response returns through the still-open
http-invocationconnection.
The request is never dropped. The caller waits longer on a cold start, but the request completes. This is only possible because the queue buffers it.
| NATS JetStream | Knative | |
|---|---|---|
| Requests during scale-up | Buffered, zero dropped | Fail / timeout |
| Cold start behavior | Queue buffers, pod starts | Requests may face timeout or retry pressure during long cold starts |
| Multi-cluster routing | Per-cluster durable consumers | Single cluster only |
| Operational footprint | Purpose-built GPU inference platform | Requires full Knative stack |
Multi-Cluster by Design #
Each GPU cluster runs its own NVCA. NATS JetStream subjects are scoped per cluster:
Creation: Create.NVCA.*.{clusterID}.*.*
Termination: Terminate.NVCA.{clusterID}
Consumer: {streamName}-{clusterID} (durable, per cluster)A single control plane can manage GPU clusters across on-prem H100s, cloud H200s, GB200 NVLink nodes, and cloud provider partners simultaneously. The invocation plane routes based on the function deployment specification.
Setting Up Locally (What Works Without NGC Access) #
You can bootstrap the cluster and fake GPU layer without NGC credentials. The NVCF services deployment is what requires the nvcf-onprem org access.
# Clone the repo
git clone https://github.com/nvidia/nvcf
cd nvcf/examples/self-hosted-local-development
# Bootstrap k3d cluster (6 nodes) + KWOK + fake GPU operator
# This works fully without NGC
./setup.sh
# Verify fake H100 nodes are registered
kubectl get nodes -l run.ai/simulated-gpu-node-pool=default
# NAME STATUS ROLES GPU
# k3d-nvcf-agent-3 Ready <none> 8x NVIDIA-H100-80GB-HBM3
# k3d-nvcf-agent-4 Ready <none> 8x NVIDIA-H100-80GB-HBM3
# Deploy NVCF stack (requires NGC nvcf-onprem access)
helm registry login nvcr.io -u '$oauthtoken' -p "${NGC_API_KEY}"
HELMFILE_ENV=local helmfile syncThe fake GPU operator from run-ai/fake-gpu-operator adds nvidia.com/gpu extended resources to real Kubernetes nodes. Pods schedule and run. CUDA calls fail since there is no real GPU, but all NVCF orchestration, NATS dispatch, and scale-to-zero logic works exactly as in production.
How NVCF Compares #
| Category | NVCF | KubeRay | KServe | Knative Serving |
|---|---|---|---|---|
| Primary workload | Long-running GPU inference | Ray/Python distributed workloads | Multi-framework ML serving | Stateless HTTP services |
| Scale-to-zero | Durable NATS buffering | Ray autoscaling | Typically relies on Knative-style autoscaling | Request buffering with timeout/retry pressure during long cold starts |
| Multi-cluster | Built-in | Primarily single cluster | Primarily single cluster | No native multi-cluster orchestration |
| Function abstraction | Helm function type | No native function abstraction | No native function abstraction | No native function abstraction |
| GPU orchestration | KAI Scheduler + DRA integration | Standard Kubernetes scheduling | Standard Kubernetes scheduling | Standard Kubernetes scheduling |
KubeRay and NVCF are not competitors. You should be able to run Ray Serve under KubeRay as a NVCF function.
What the Open Source Release Actually Changes #
Inspectability. Enterprises can now validate NVIDIA’s architectural decisions directly from the source code instead of treating the platform as a black box.
Customization. You can modify the autoscaler Rust loop, add NATS auth strategies, extend the MiniService controller, or build new CLI commands. Earlier, these internals were largely inaccessible outside NVIDIA-managed environments.
Links #
-
Repo: github.com/nvidia/nvcf
-
My PR: NVIDIA/nvcf#13
-
NGC access issue: NVIDIA/nvcf#14
-
Contribute / contact team: nvcf-interest@nvidia.com
Saiyam is working as Head of DevRel at vCluster Labs. He is the founder of Kubesimplify, focusing on simplifying cloud-native & AI infrastructure. He is KubeCon Co-chair and has worked on many facets of Kubernetes, including machine learning platforms, scaling, multi-cloud, & managed Kubernetes services. When not coding, Saiyam contributes to the community by writing blogs and organizing local meetups for Kubernetes and CNCF. He is also a CNCF TAG OpsRes Chair & can be reached on Twitter @saiyampathak.
Get new posts in your inbox.
Spotted a typo or want to improve this post? Edit on GitHub →