Topic
1 article
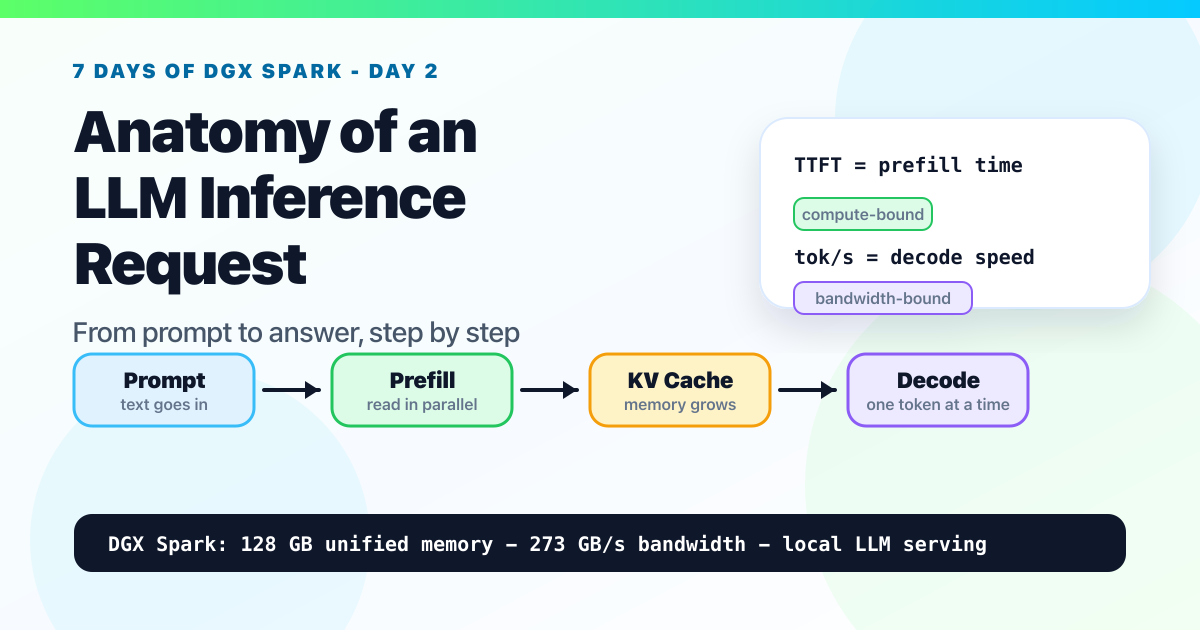
A beginner-friendly walkthrough of tokenization, prefill, KV cache, decode, batching, TTFT, and why memory bandwidth shapes local LLM performance on NVIDIA DGX Spark.