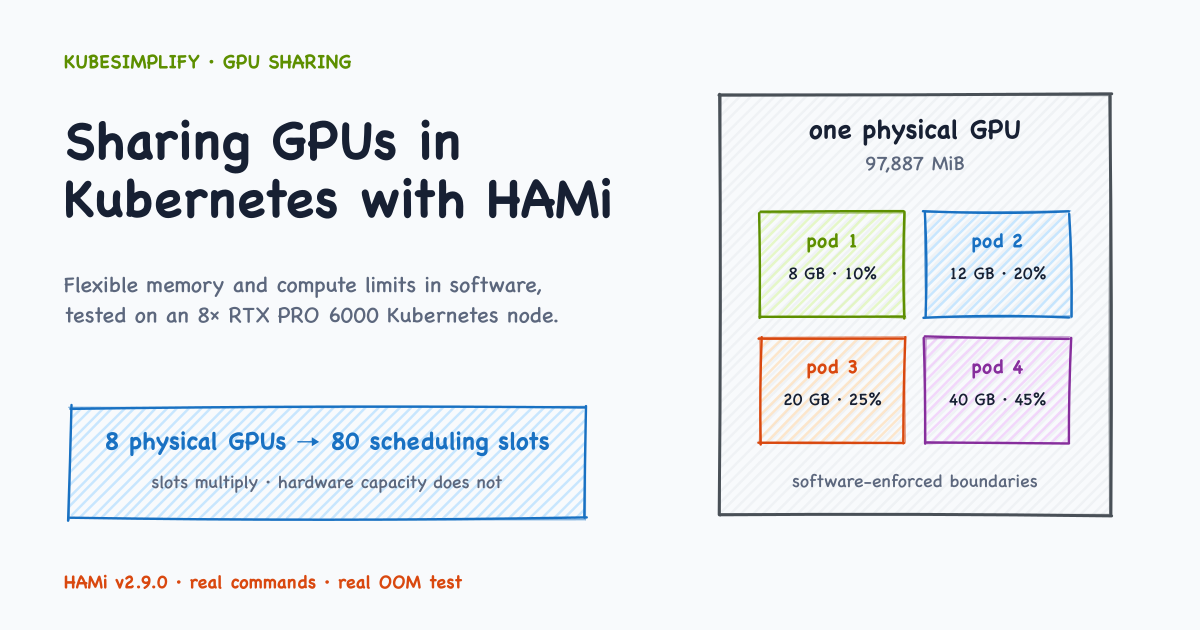
How to Share GPUs in Kubernetes at Scale with HAMi (Software vGPU Slicing)
Share NVIDIA GPUs in Kubernetes with HAMi software vGPU slicing: memory and compute limits, Helm configuration, a verified PyTorch manifest, a real RTX PRO 6000 OOM test, and Prometheus monitoring.
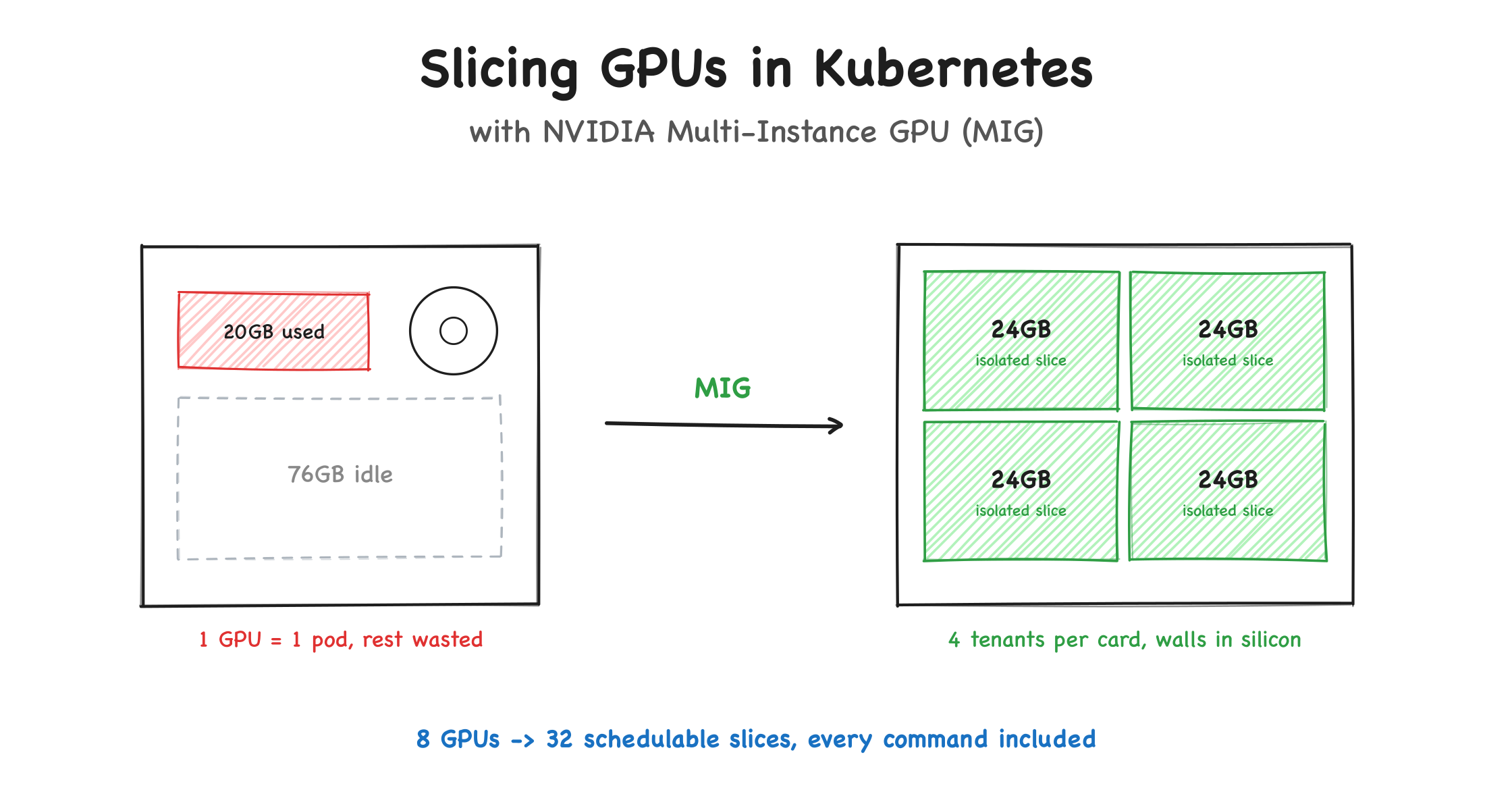
Slicing GPUs in Kubernetes with NVIDIA Multi-Instance GPU (MIG)
GPU sharing in Kubernetes explained: time-slicing vs MPS vs MIG, every nvidia-smi command to enable and disable MIG on one GPU or eight, GPU Operator automation, pitfalls, and DCGM monitoring.
Day 5: Local LLM Inference Engines, Wrappers, and What to Pick
A beginner-friendly guide to local LLM inference, with the same Qwen model tested through Ollama, llama.cpp, Docker Model Runner, vLLM, SGLang, and TensorRT-LLM on NVIDIA DGX Spark.
Bonsai 27B on RTX PRO 6000 vs DGX Spark: what actually works
Real Bonsai 27B benchmarks on an RTX PRO 6000 and a DGX Spark, including the supported llama.cpp setup, ternary vs 1-bit results, and speculative decoding.
Introducing kiac: Real Kubernetes Nodes on Your Mac, Each Its Own Lightweight VM
kiac runs local Kubernetes on macOS where every node is its own lightweight VM via apple/container: kubeadm or k3s flavors, Cilium on a custom kernel, built-in LoadBalancer, Grafana, Gateway API, and clusters that survive reboots.
LLM Costs and Observability with agentgateway on Kubernetes (Part 2)
Part 2: scrape agentgateway with Prometheus, build a Grafana dashboard of token cost and per-tool usage, see blocked tool calls, and alert on spend.
Controlling MCP Tools with agentgateway on Kubernetes (Part 1)
Run AI agents behind agentgateway on Kubernetes: route their LLM and MCP tool calls through one proxy, keep secrets out of the agent, and block tools by policy.
Day 4: Quantization Demystified. BF16, FP8, NVFP4, MXFP4, INT4, GGUF, and Why It All Matters
A practical, beginner-friendly guide to BF16, FP8, NVFP4, MXFP4, INT4, and GGUF Q4_K_M on NVIDIA DGX Spark. Bytes per parameter, quality vs size, and which format to pick when.
Day 3: The DGX Spark Unpacked. GB10, Unified Memory, sm_121, and the One Reason This Hardware Exists
A practical teardown of NVIDIA DGX Spark's GB10 Grace Blackwell Superchip, unified memory, sm_121, NVFP4 tensor cores, memory reporting, and decode limits.
Wandler: Local OpenAI-Compatible Inference With Transformers.js and WebGPU
A practical Wandler deep dive with a local M1 Max WebGPU demo, real latency numbers, architecture diagrams, and getting-started commands.
mlxcel: A Rust-Native Inference Engine for Apple Silicon, Tested on My M1 Max
Day-one deep dive into mlxcel v0.1.0, a Rust-native MLX inference engine. Real M1 Max benchmarks vs mlx-lm and Ollama on Llama 3.2 3B and Qwen 2.5 7B, with architecture diagrams and an honest take on TurboQuant.
Day 2: Anatomy of an LLM Inference Request. From Prompt to Answer, Step by Step
A beginner-friendly walkthrough of tokenization, prefill, KV cache, decode, batching, TTFT, and why memory bandwidth shapes local LLM performance on NVIDIA DGX Spark.
How kube-proxy Actually Works: iptables, IPVS, and nftables Inside Out
How kube-proxy turns Kubernetes Services into kernel rules. iptables, IPVS, nftables packet paths and which to pick in 2026. Verified against k/k 1.36 source.
Day 1: The Local LLM Revolution. Why Your Desk Just Became the New Datacenter
Why local LLMs are becoming practical in 2026, what changed across open weights, hardware, and inference software, and why DGX Spark makes the desk feel like a small AI lab.
How Kubernetes EndpointSlices Actually Work (and Why Endpoints Had to Die)
A Service has no pod IPs in it. We covered that in the last post. So somewhere, something is keeping a list of every pod IP that matches the Service's…