We all agree that in recent years, AI has taken the world by storm. With tools like ChatGPT and platforms developed by OpenAI leading the charge — AI is being used in many industries to make work easier, provide helpful insights, and boost productivity. According to The State of AI 2023 by McKinsey, AI adoption has increased by over 60% in the past year alone, with businesses using AI to stay ahead and innovate!
Given how AI is making a significant impact across industries, it makes sense to ask — why not use AI in managing Kubernetes?
Kubernetes is one of the most widely adopted open-source container orchestration platforms. Its powerful features make it a top choice for automating the deployment, scaling, and management of containerized applications. However, as Kubernetes environments grow larger, they can become complex and difficult to manage. Troubleshooting issues at scale can be particularly challenging.
This is where AI can make a big difference! By adding AI to the Kubernetes workflow, we can make the management process smarter and more efficient. AI can help diagnose and resolve issues quickly, automate routine tasks, and provide insights that enhance decision-making.
Building upon this narrative, in this blog we’ll explore k8sGPT — a powerful tool that brings the capabilities of AI to change the way you manage Kubernetes, making it easier to solve problems, make decisions, and keep things running smoothly.
Introducing K8sGPT - Kubernetes Troubleshooting with AI #
K8sGPT is a tool for scanning your kubernetes clusters, diagnosing and triaging issues in simple english. It has SRE experience codified into its analyzers and helps to pull out the most relevant information to enrich it with AI.
K8sGPT is a CNCF sandbox project designed to simplify Kubernetes management using AI and natural language processing. It integrates with various AI backends, such as OpenAI, Azure OpenAI, and Google Gemini, to provide clear and actionable insights into your Kubernetes environment. These insights are presented in a user-friendly format, making them easy to understand and act upon.
Some of its key features include:
Cluster Scanning - Automatically checks your Kubernetes clusters to find any issues.
Issue Diagnosis - Quickly identifies problems and explains them in simple language.
Actionable Advice - Gives practical tips on how to fix issues.
Anonymization - Protects sensitive data by hiding it during analysis.
Extensibility - Allows you to add custom analyzers to meet your specific needs.
These features make K8sGPT a valuable tool for anyone managing Kubernetes environments. It helps you find and fix problems faster, automate routine tasks, and make better decisions. In the next sections, we'll see how these features work through practical demos and real-world examples.
In the upcoming sections where we discuss different functionalities of K8sGPT, we’ll mainly focus on using the CLI.
Based on your operating system, there various methods of installing the k8sgpt CLI which you can check out in the installation guide. We will be using the following commands to install it via homebrew:
brew tap k8sgpt-ai/k8sgptbrew install k8sgpt
Once the installation is complete, use the following command to verify whether it was installed correctly:
Before we move forward with using K8sGPT to analyse our cluster, we need to authenticate it with an AI backend. A Backend (also called Provider) is a service that provides access to the AI language model. K8sGPT supports a lot of different AI backends — so there are several options to choose from!
Tip: Each AI backend has its own strengths and weaknesses, so it is important to choose the one that is right for your needs.
To know all the supported AI backends, we can use the k8sgpt auth command as shown below:
For this tutorial, we’ll be using Ollama to run the Llama 3 (latest as of today) LLM locally on our machine — at zero cost!
Note: OpenAI is the default backend for K8sGPT and is recommended by the community for its powerful language models and accurate results. However, for local testing and demo purposes, free, open-source options are also supported, such as Ollama, Local AI, and FakeAI. Remember, better language models lead to more accurate results!
To get things started, make the sure the ollama server is up and running using the following command:
ollama serve
To authenticate K8sGPT with ollama, we’ll be using the k8sgpt auth command as shown below:
Use the following command to apply this to our cluster:
kubectl apply -f broken-pod.yaml
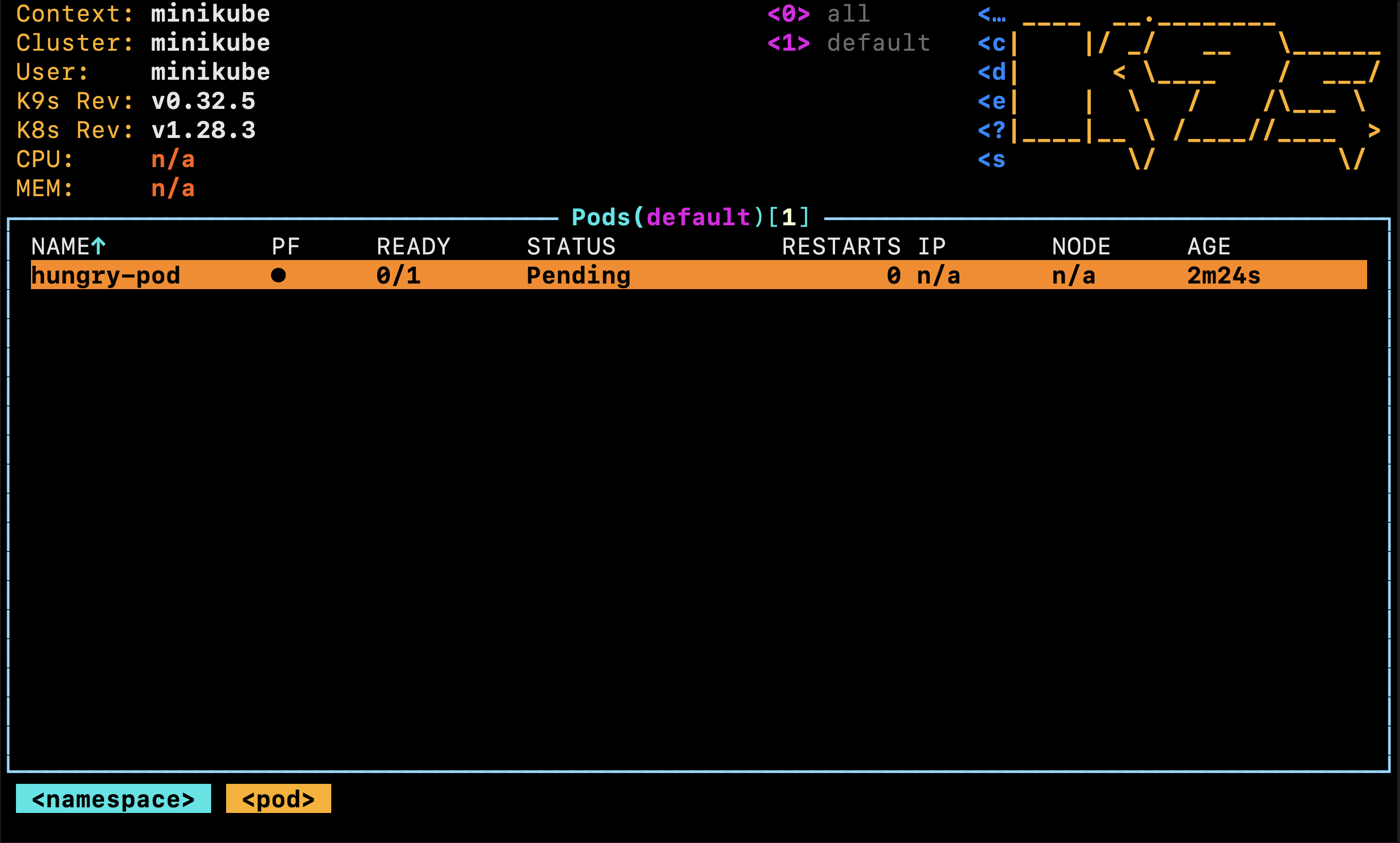
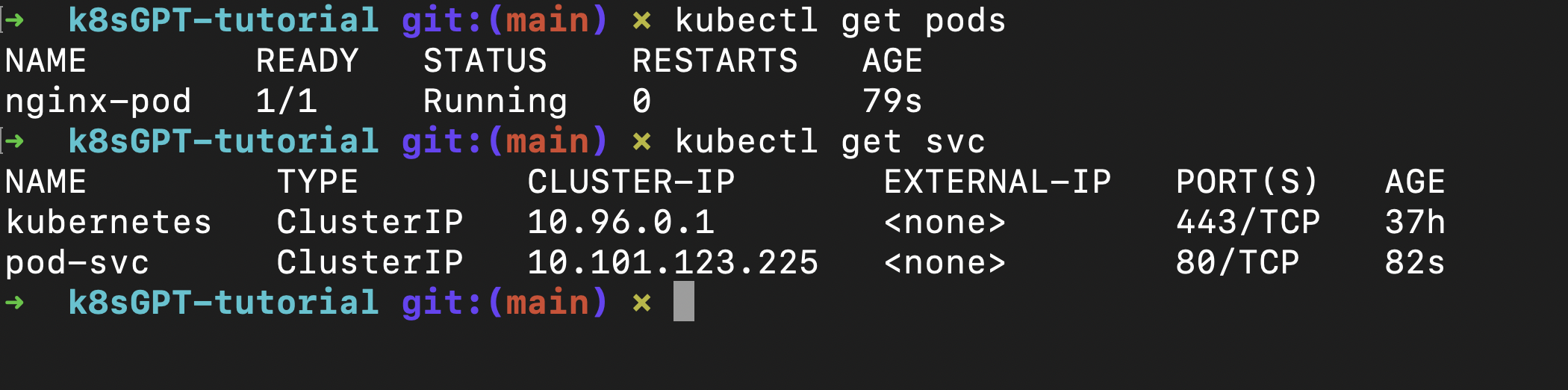
You will notice that the pod is currently in a Pending state and remains that way — which means there’s something wrong here!
If you’re familiar with the basic concepts of Kubernetes, your default approach will be to check the pod events using the following command:
kubectl describe pod hungry-pod
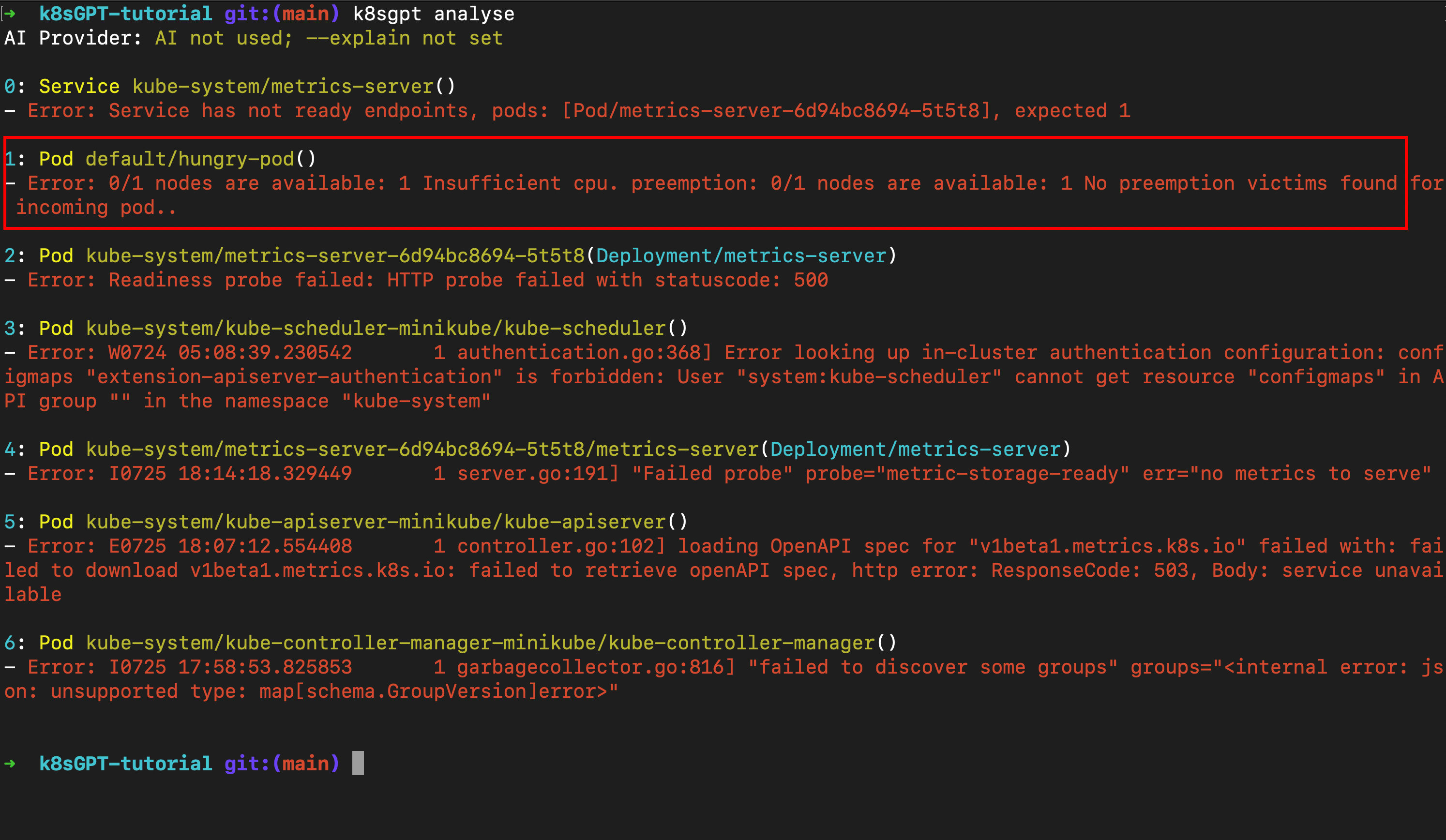
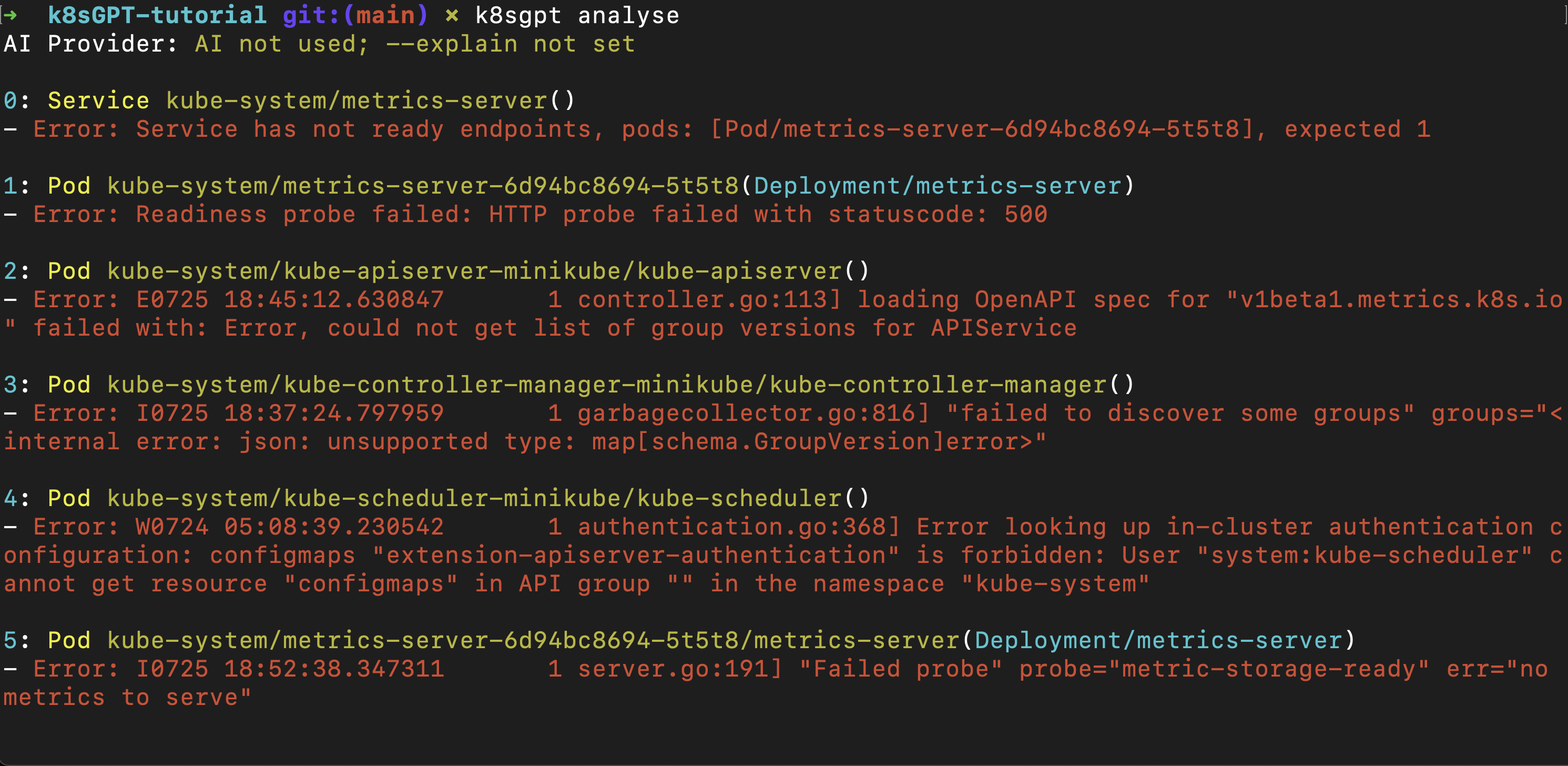
But, lets see how far can we go with using AI to know more! Run the following command to to scan the entire cluster and find issues:
k8sgpt analyse
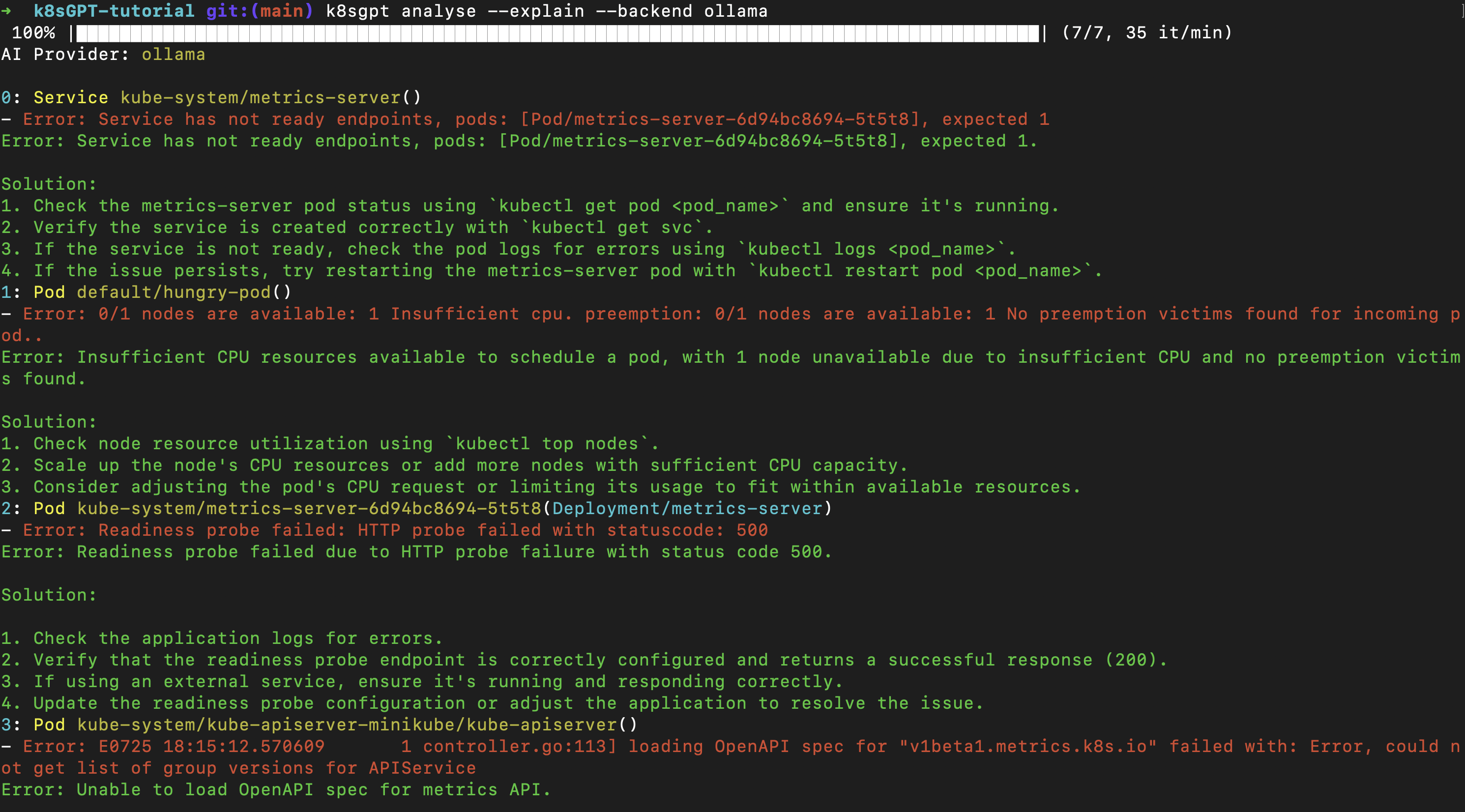
According to this, there are no nodes with sufficient CPU resources available to schedule the incoming pod. That’s helpful — let’s take this a step further. Run the following command to get additional information about the error and get recommendations by AI on how to fix the issues:
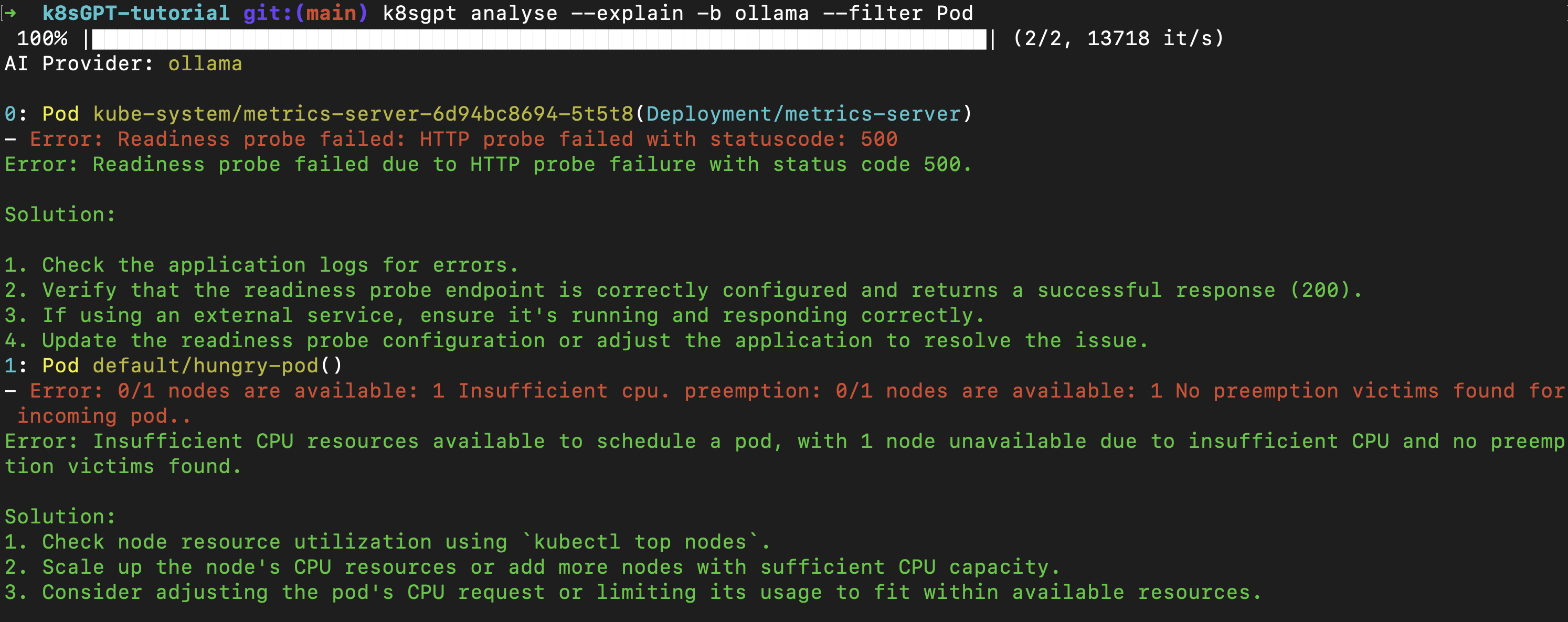
k8sgpt analyse --explain --backend ollama
Here are two things the AI provides for each error:
Explaining the error in simple language
Giving potential solutions to debug and fix the issue
We can try all these solutions to solve our pod issue, but to me, the simplest solution is the 3rd one — adjusting the pod’s CPU requests.
Let us first check the CPU capacity of our node by using the following command:
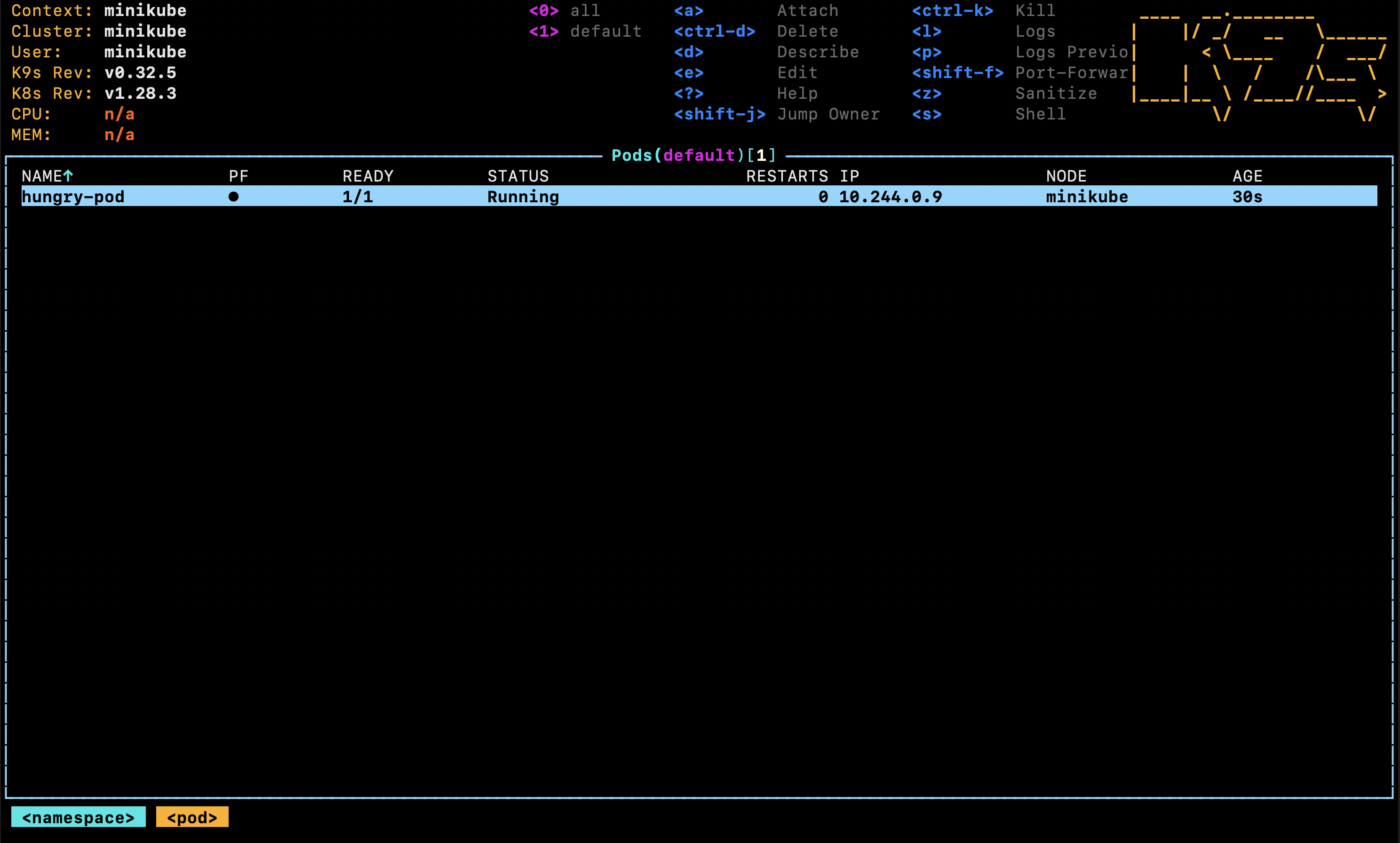
Once applied, you’ll notice that there no errors. The pod is in running state and the service has been created:
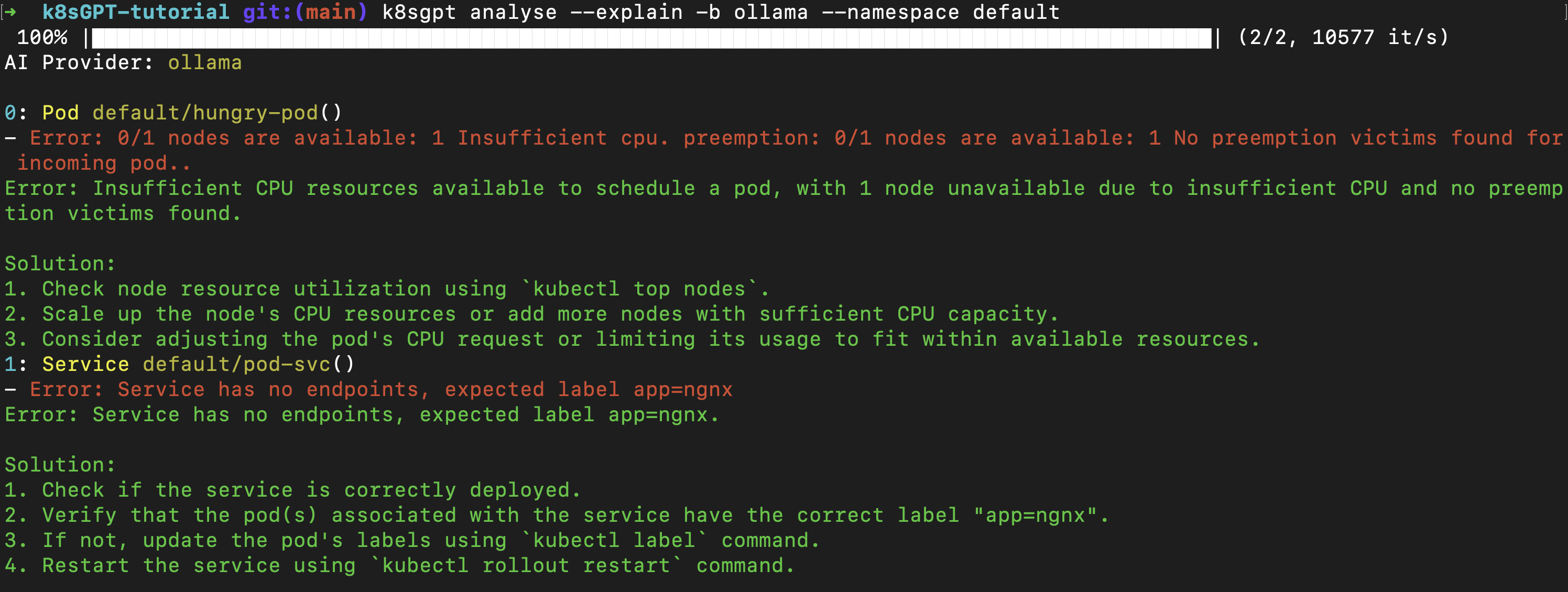
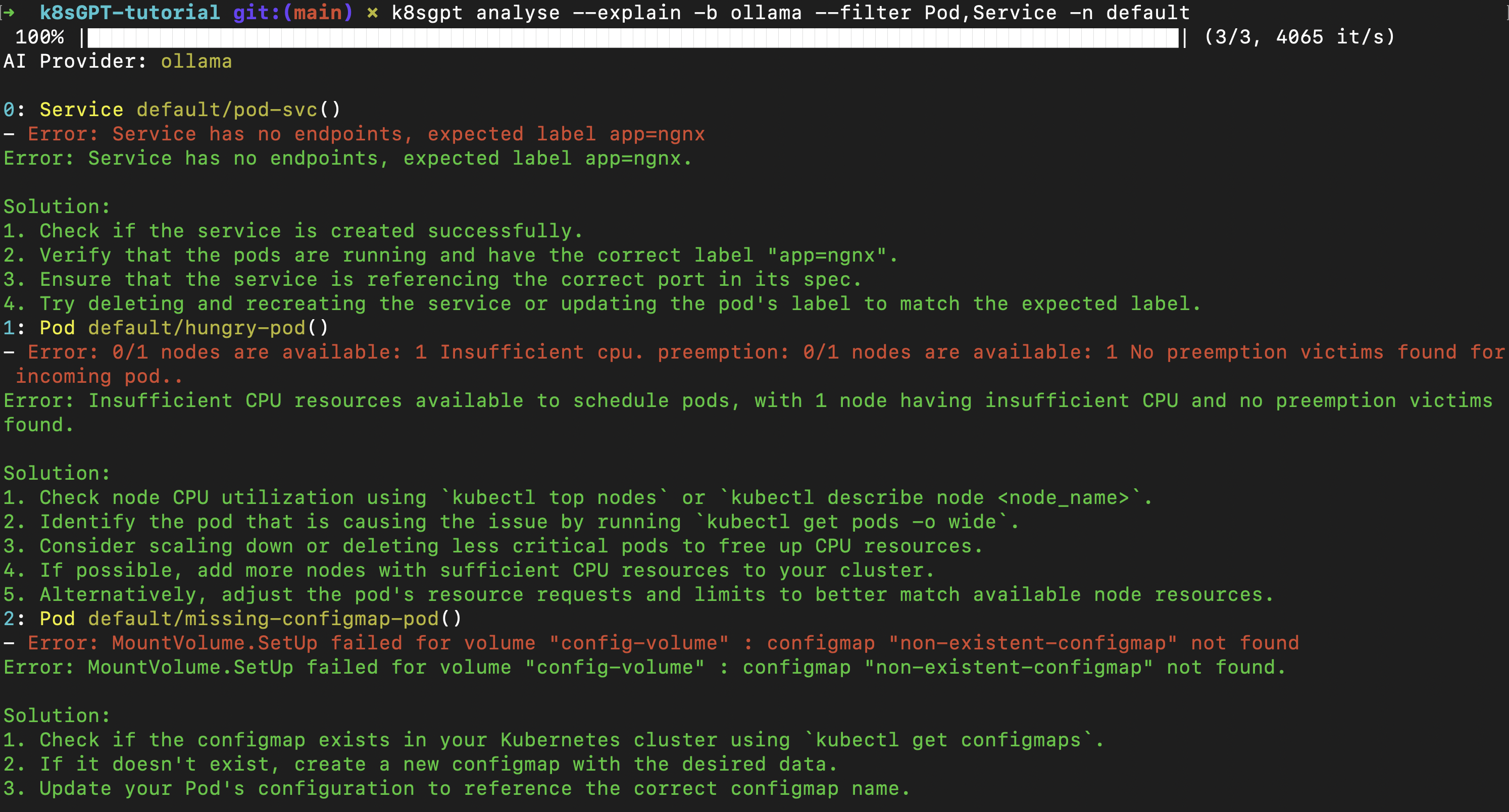
But sometimes looks can be deceiving! Let us use K8sGPT to scan for issues that may not be visible and provide potential solutions to fix them:
k8sgpt analyse --explain -b ollama
Caught it! We have an issue with the service - there are no available pods that match the service's selector criteria (labels in this case) to route traffic to.
To fix this, either we can change the service’s labels or the pod’s label. Use the following command to quickly change the pod labels to match the service:
kubectl label pod nginx-pod app=ngnx --overwrite
# Outputpod/nginx-pod labeled
Now, if we run the k8sgpt analyse command again, it won’t detect any errors with our pod and service — because we’ve solved it 🎉
In the previous section, you might have noticed that the k8sgpt analyse command gives a list of all the issues within our cluster, covering all Kubernetes resources. In a demo scenario (similar to what we have here), we may only have a few Kubernetes resources deployed in our cluster — making it relatively easier to navigate our target resources.
But let’s get real here! In a real-world production scenario, you may have 1000s of resources deployed, and it may get difficult to navigate and find them following this format, right?
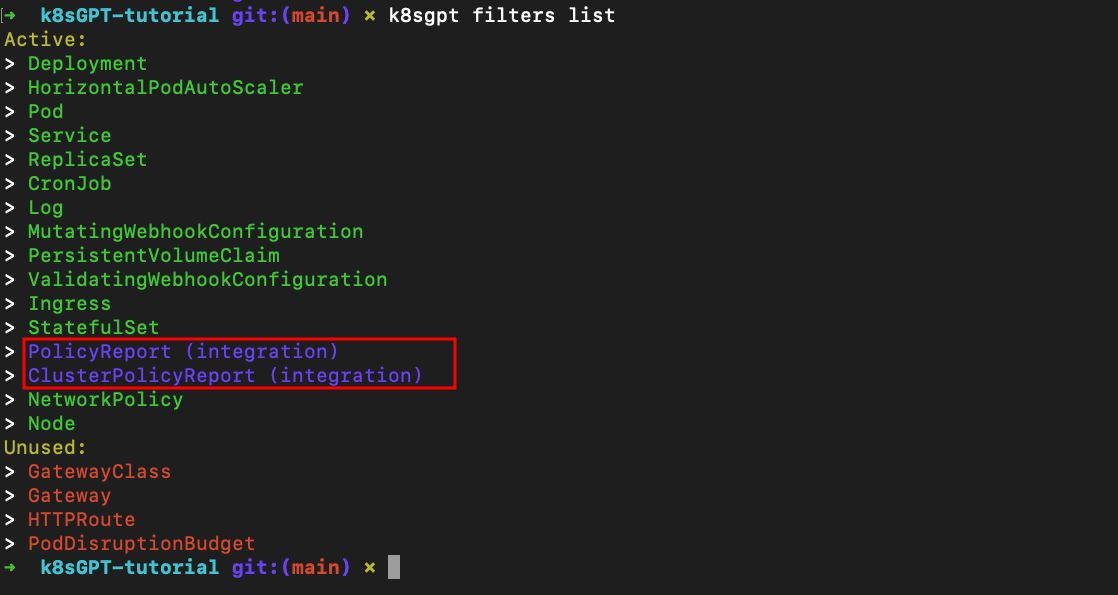
Interestingly, K8sGPT does this for you using filters. Filters are a way of selecting which resources you wish to be part of the default analysis.
To check the list of available filters, use the following command:
Apart from the built-in filter support (which we’ll also expand in the upcoming section), there are two additional flags worth highlighting:
Output JSON Flag
The --output json flag generates the analysis output in JSON format. This is particularly useful when you want to integrate K8sGPT with other tools or automate tasks, as JSON is a widely accepted format for data exchange. By using this flag, you can easily parse and process the output with scripts or software applications, allowing for seamless integration into your existing workflows. Here's how you can use it:
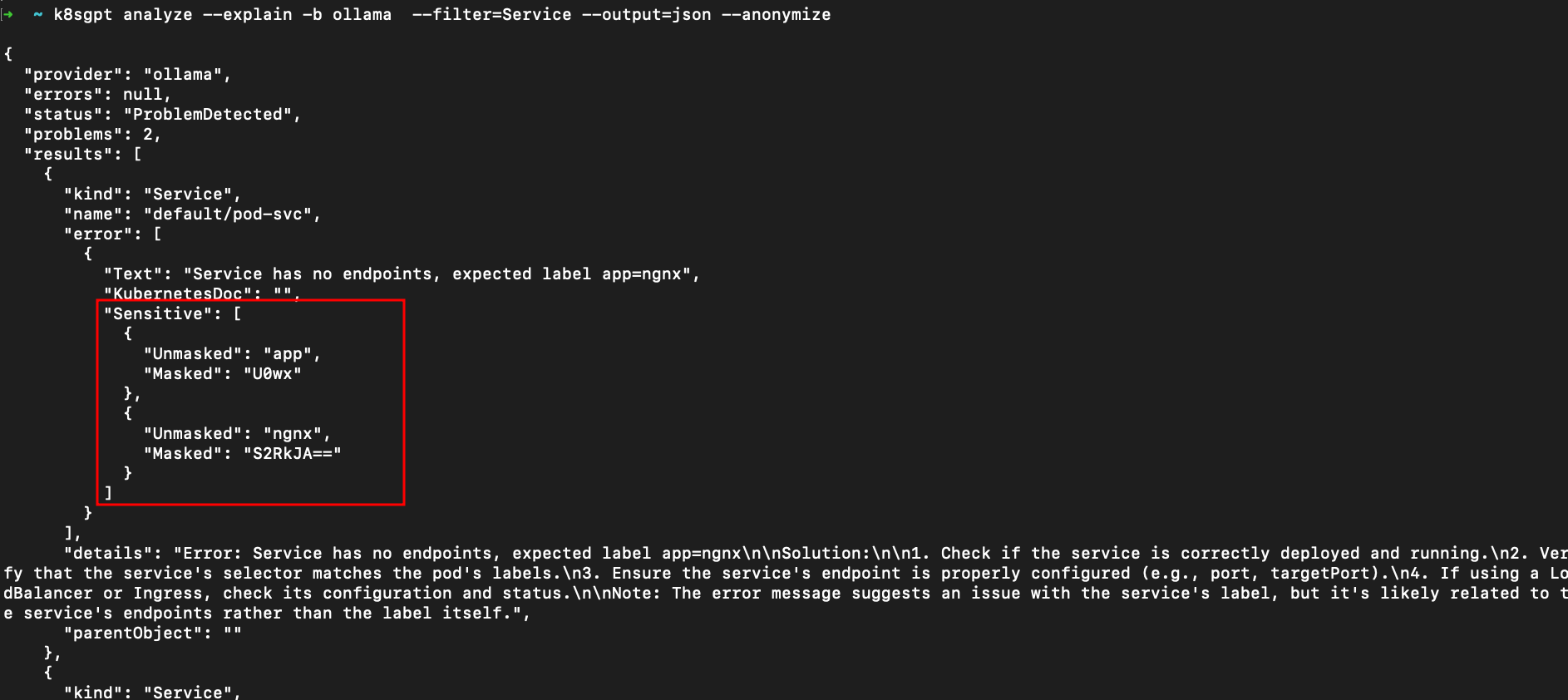
If you’re concerned with providing sensitive data about your workloads to OpenAI or other AI backends, the --anonymize flag is useful for you. When used with the k8sgpt analyse command, this flag masks sensitive data such as Kubernetes object names and labels before sending it to the AI backend for analysis.
During the analysis, K8sGPT retrieves sensitive data, which is then masked before being sent to the AI backend. The backend receives the masked data, processes it, and returns a solution to the user. Once the solution is returned to the user, the masked data is replaced with the actual Kubernetes object names and labels. Here’s how you can use it:
When we talk about any tool in the cloud-native ecosystem, the main value lies in how well it integrates with other tools from the CNCF Landscape.
Despite being an early-stage project, K8sGPT offers useful integrations that enhance its default analysis capabilities. These integrations provide additional features for scanning, diagnosing, and triaging issues in Kubernetes clusters.
In this section, we’ll focus on the Kyverno integration, which was released in the latest v0.3.39 (at the time of writing this blog).
Note: To follow along, ensure you are on the latest version of the K8sGPT CLI.
To get started, use the following command to list all the available integrations:
After the installation, apply a simple validation policy that ensures a label called team is present on every Pod. Use the following YAML manifest to apply the policy to your Kubernetes cluster:
After this, if you try to create a Pod without the team label, the operation won’t be allowed!
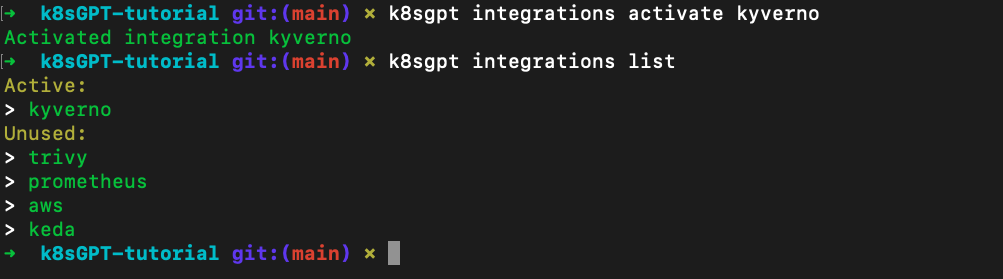
Once Kyverno is installed and verified, activate it as a K8sGPT integration using the following command:
k8sgpt integrations activate kyverno
With the Kyverno integration, we get two new filters:
PolicyReport
ClusterPolicyReport
You can use the following command to get a list of updated filters:
k8sgpt filters list
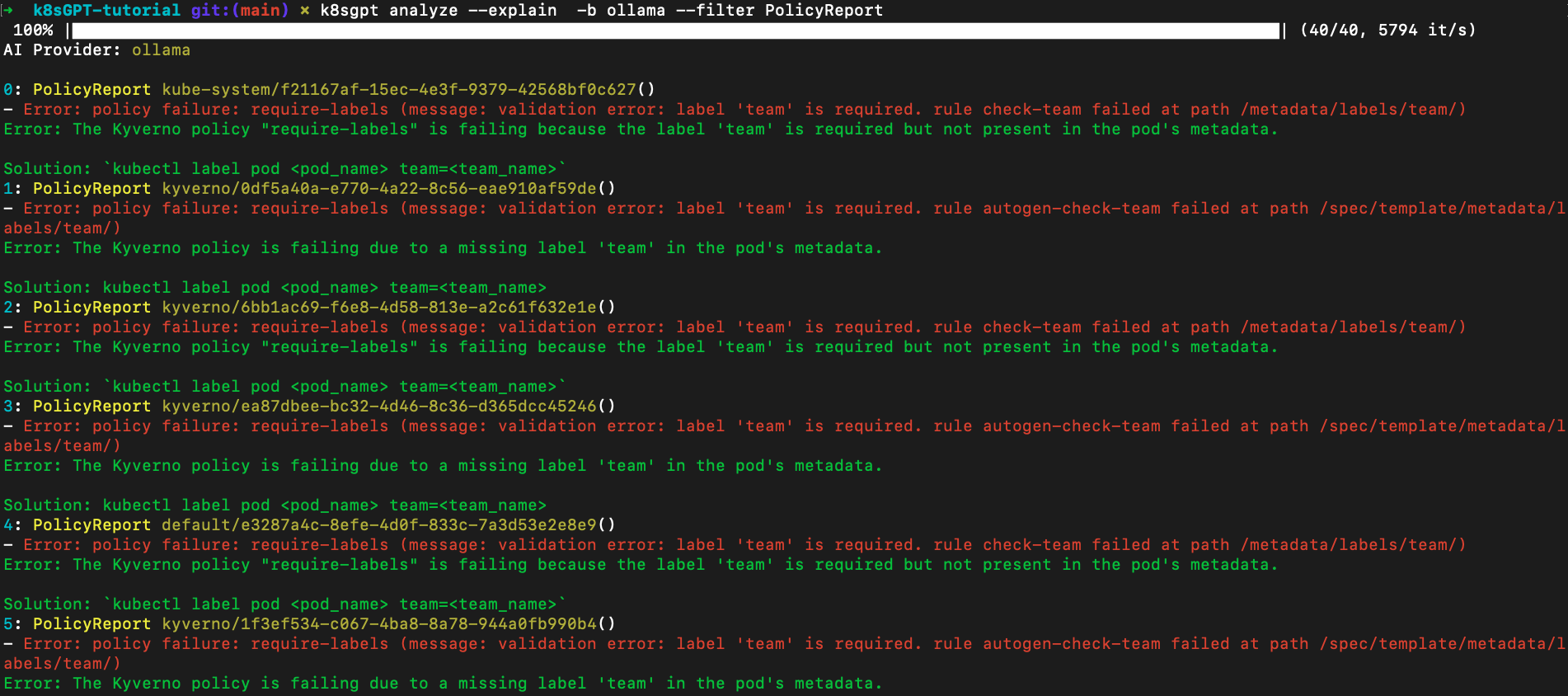
We can now use one of these new filters as part of the k8sgpt analyze command to filter out relevant information about Kubernetes resources. Below is an example using the PolicyReport filter:
k8sgpt analyze -b ollama --filter PolicyReport
It’s pretty similar to using the good old: kubectl get policyreport command — as both retrieve information about policy compliance in our Kubernetes cluster, the only difference being, now we also get solutions to fix the issues!
Note: At the time of writing this article, the Kyverno integration is newly added and is at its initial stages (check out the PR), so you may encounter some issues. Feel free to open an issue if you encounter any problems while working with it!
It's important to note that the example above is shown in a demo scenario, which might not showcase its full potential. However, imagine a production cluster with thousands of pods running — the accessibility and insights provided by this kind of integration would be invaluable in such a scenario!
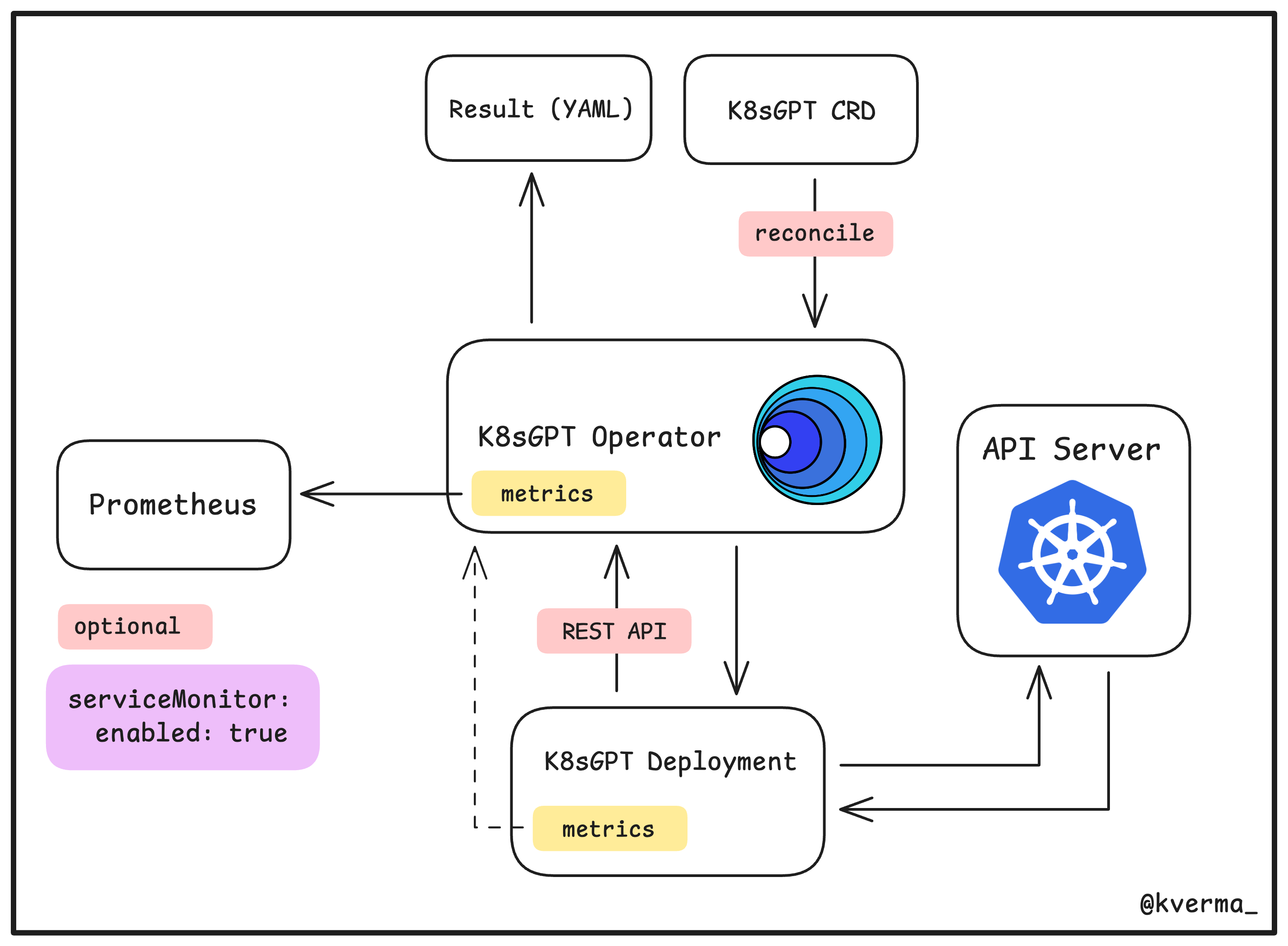
The K8sGPT CLI is a great way to get started and perform ad-hoc scans in a cluster, but it involves manually running a command for each analysis. What if you want continuous 24/7 scans in the cluster? For this, you can install K8sGPT as a Kubernetes operator, which runs as a Kubernetes Custom Resource and produces reports stored in your cluster as YAML manifests.
These are all the different components that the k8sGPT operator installs and manages:
To learn more about installing and setting up the operator, check out the documentation.
Note: The K8sGPT Operator can be customized by modifying the values.yaml file. To check the available customizable options, refer to the documentation.
Want to make k8sGPT to analyze your Kubernetes cluster in ways specific to your environment? K8sGPT allows you to create your own custom analyzers to fit your specific needs. This feature lets you extend the capabilities of K8sGPT by writing your own code to analyze your Kubernetes cluster in ways that are unique to your environment. Whether you need to check for specific configurations or monitor custom metrics, custom analyzers give you the flexibility to tailor the tool to your requirements.
To know more about how to create and use custom analyzers, refer the custom analyzers guide.
Does your team operate via Slack? K8sGPT also offers seamless integration with Slack, making it easier to get notifications and updates directly in your Slack channels. This feature ensures that your team stays informed about the health and status of your Kubernetes clusters without having to leave their communication platform. Setting up Slack integration allows you to receive real-time alerts and insights, helping your team to respond quickly to any issues.
These features are certainly powerful additions to K8sGPT, enhancing its functionality and making it even more useful for managing your Kubernetes clusters.
K8sGPT is a powerful tool that brings the capabilities of AI to Kubernetes management, making it easier to diagnose and resolve issues, automate routine tasks, and gain valuable insights. With features like custom analyzers and Slack integration, you can tailor the tool to fit your specific needs and keep your team informed in real-time.
We've covered the essentials, from installation to advanced features. Now, it's your turn to explore and see how K8sGPT can simplify your Kubernetes operations. Give it a try, and don't hesitate to share your experiences or join the community for further discussions.
Kunal is a DevOps and Cloud Native Advocate with a passion for Open Source. He's been involved in the DevOps and open-source ecosystem for 1.5+ years and has a strong experience in public speaking, community management, content creation etc. He has experience working on and contributing to some of the major projects in the CNCF, including Kubernetes, Layer5 and others. He always strives to empower others with my experiences and believes in growing with the community!