Keptn: Getting started
Keptn is an event-driven orchestration engine for cloud-native apps. It is a CNCF incubating project. It does a lot of things, some of them include: -…


On this page (5)
Keptn: #
Keptn is an event-driven orchestration engine for cloud-native apps. It is a CNCF incubating project. It does a lot of things, some of them include:
- Decoupling tools from workflows.
- Automate multi-stage delivery.
- Making reusable pipelines.
- Making delivery process more efficient, by making them asynchronous.
- Reducing manual testing and validation.
- Automated Operations.
We will explore all the above stated aspects one by one, but before that we need to understand "Why Keptn". So, let's get back to how does a typical, application release cycle looks like, without Keptn.
Without Keptn: #
As we know, there are multiple stages and environments, when it comes to delivering software, from building to all the way delivering it to the end users. Development stage, pre-production stage and production stage. All these stages need different type of testing and manual approvals, before deploying it to the next stage.
When it comes to deploying it into production. There are different strategies, like direct, canary and blue-green deployment. They prevent the service denial in case things go wrong in the production stage. Let's take an example.
There is an application, it is a blogging site like hashnode. The developers decided to add a new feature into it. What will happen ?
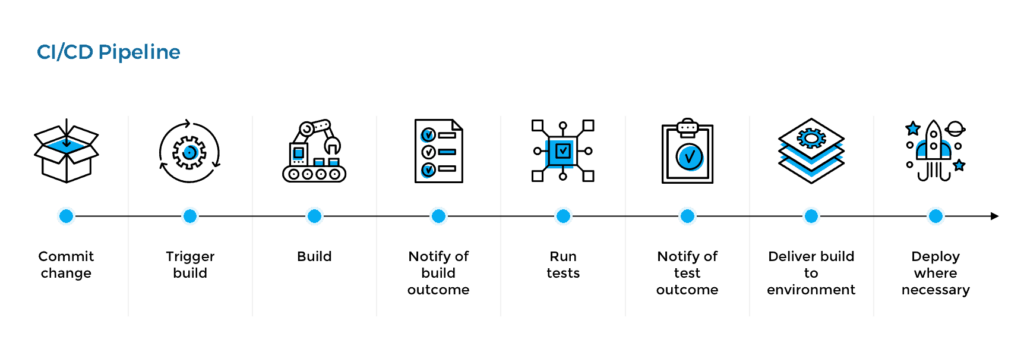
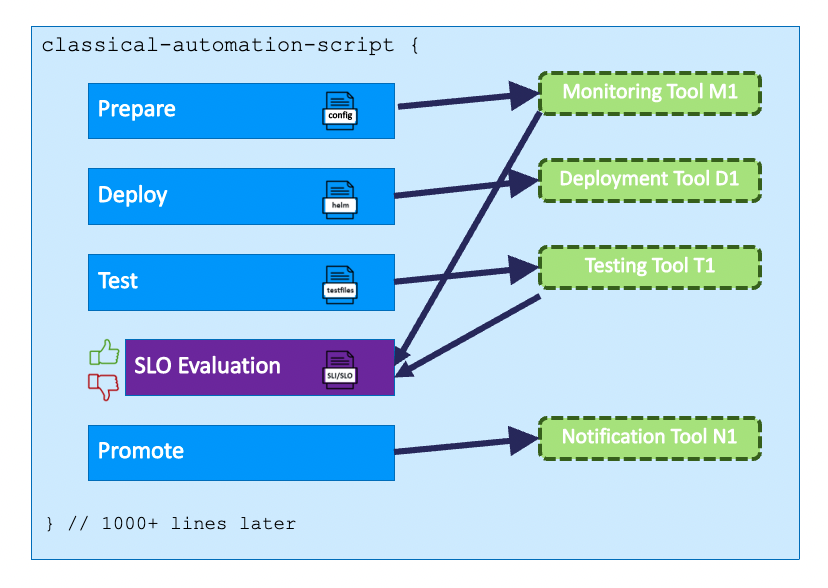
Above is an image of a typical CI/CD pipeline. It consists of actions that take place when they try to add a new feature in the app. The pipeline is an automation script, with thousands of lines of code, with step-by-step process, tool integration. It is literally very hard to maintain.
1: Commit change:
- The developers coded the new feature and committed it into the repository.
- It will automatically trigger the build stage.
2: Build stage:
- The feature is built and gets ready for being tested.
3: Testing:
- Does the feature break the application ? If yes, it won't be sent to the next stage.
- If everything works fine, it is sent to the next step.
4: Pushing to registry and deploying:
- Now the built image is pushed to the registry.
- It is then further deployed into the Dev environment.
But for the end users to see the changes, the application must be deployed to production, dev and pre-prod stages are just for testing, the application is only accessible from production.
We cannot do that directly deploy to production using a normal CI/CD pipeline, In the dev stage the application is just tested for bugs, We don't know how it will perform when exposed to real users. Our application must pass functional as well as performance test before it can be deployed into production.
So we use a multi-stage process.
Multi stage process: #
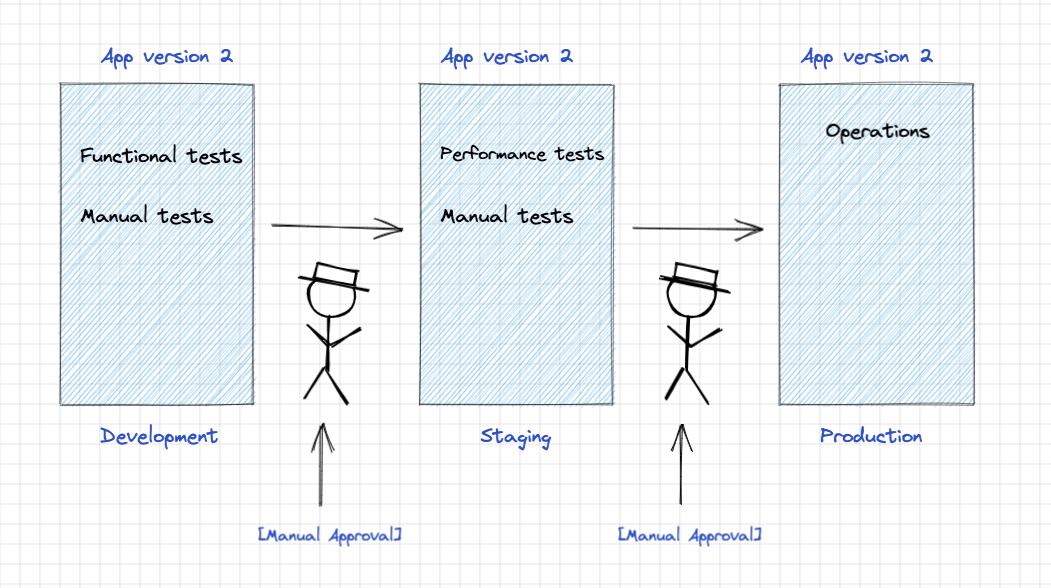
1: Development stage: #
- The application is deployed in dev stage and automated functional tests are performed here.
- Is it working ? Or does the new feature break the application ? If yes, we cannot send it to the next stage.
- Manual tests are also used to increase the reliability of the build.
- On passing all of them, A person tallies the data produced via testing and manually approves it for the next stage.
2: Pre-production stage: #
- The application is deployed in pre-prod/staging and automated performance tests are run.
- How fast does the application respond when exposed to the user traffic ?
- Extensive manual evaluations are also done, just like Development stage, manual approval is necessary here as well.
3: Production stage: #
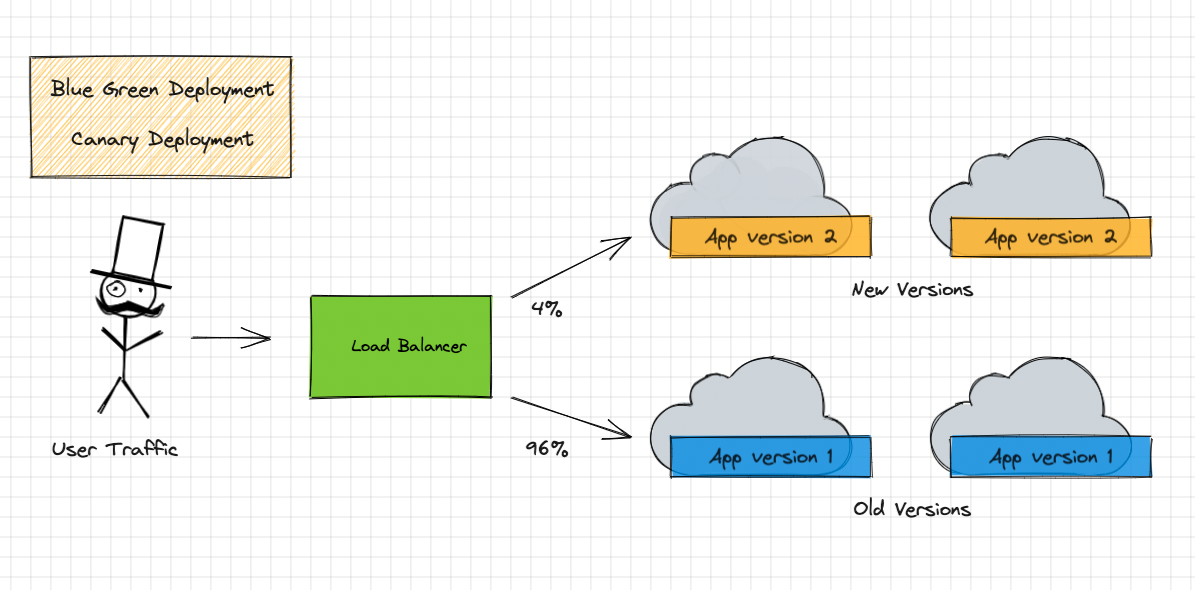
- The application is now deployed using a strategy like direct, blue-green etc.
- It deploys the feature in small chunks and a small amount of traffic is diverted to it, so that if the application breaks, the users don't lose access, they just start requesting the services running an older version.
Problems: #
-
Manual testing and approval: A lot of manual work delays the process and increases chances of manual errors.
-
Time: Doing thing manually and in a synchronous order slows the release process down.
-
Tool integration and non-reusable pipelines: There are so many tools that offer similar features.
These tools need to be integrated in the pipeline, making the pipeline non-reusable. Because even a slight version difference of a tool can break it, after-all it is just automation scripts. For any slight difference, a new pipeline must be built.
It is not so uncommon to have multiple pipelines. A company might have different teams using several of them. The team itself needs to maintain it, and it's a lot of work, because it usually uses Shell scripting.
4: Operations: Even after the application is deployed in the production. It still might break, the operations team would have to act at once, doesn't matter if it's 3 in the night. The company is loosing customers and revenue.
Too much of the problem part. Let's find the solution. Now enters Keptn!
With Keptn: #

Keptn uses declarative approach to define high level workflow. We define "What needs to be done" in a file(YAML), the Shipyard.yaml file, and keptn handles "How it will be done."
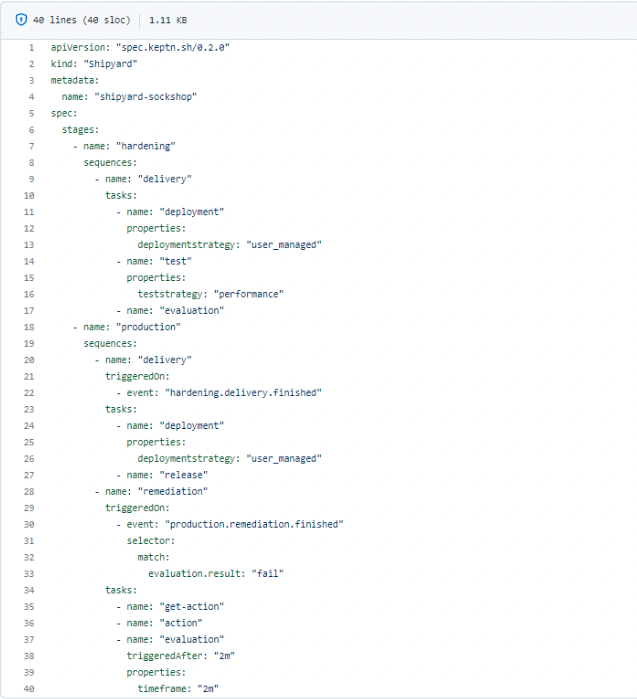
Above is an example of the shipyard file. The file is divided into multiple stages, hardening and production. Each stage contains sequences, which further contains tasks.
Just like the above-mentioned "multi-stage process", the shipyard file have stages, each stage consists of sequences like, delivery which itself will contain tasks, that are the steps needed to perform that delivery sequence. Steps like deployment, testing, evaluation etc.
This is not a shell script, it is a simple YAML file that just defines what needs to be done. It does not even contain the integration script of tools. The tools are not even mentioned !
You might be wondering :
- How do tools know that they have to perform the task ?
- What about different versions and reusable pipelines ?
- How does validation happen for the artifact to go from one stage to another, it must be manual, right ?
- Automated Operations was mention above. What about that ?
How Keptn works: #
Keptn uses events to communicate with tools, hence event-driven. The tools that have to perform the task, keep listening for the event, when received, perform the task and send back a "completed" status.
1. How do the tools know ? #
There is a Keptn Service for individual tools. It is the one listening to the keptn events, when received, translates the event into a tool-specific API call, so that the tool itself now understands what needs to be done.
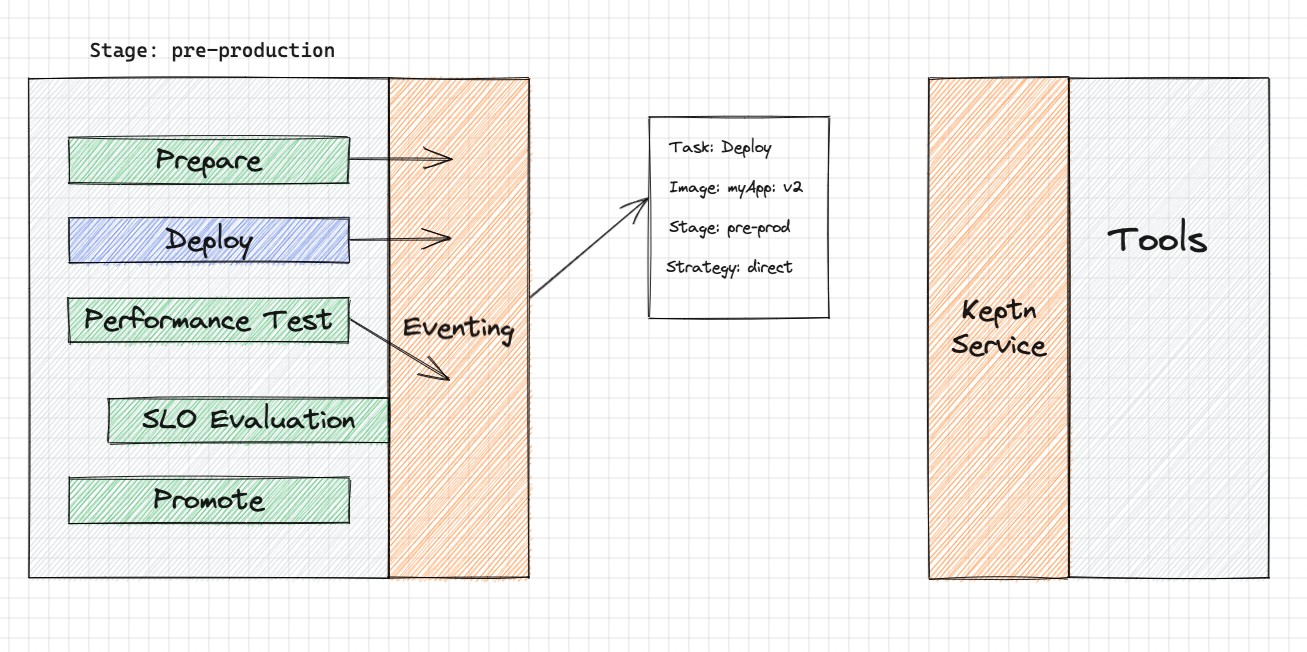
Let's take the Deployment task in the above shipyard file. After reading the file, Keptn generates events, that specifies what needs to be done. Now the deployment service, let's say Helm-service, which is constantly listening for the deployment event, tells Helm to Deploy the app in pre-prod stage.
Keptn Deployment service takes it, converts it into tools specific API calls, so that now tool itself knows what needs to be deployed, and how ! Doesn't matter what tool you use, Helm, Kubectl etc.
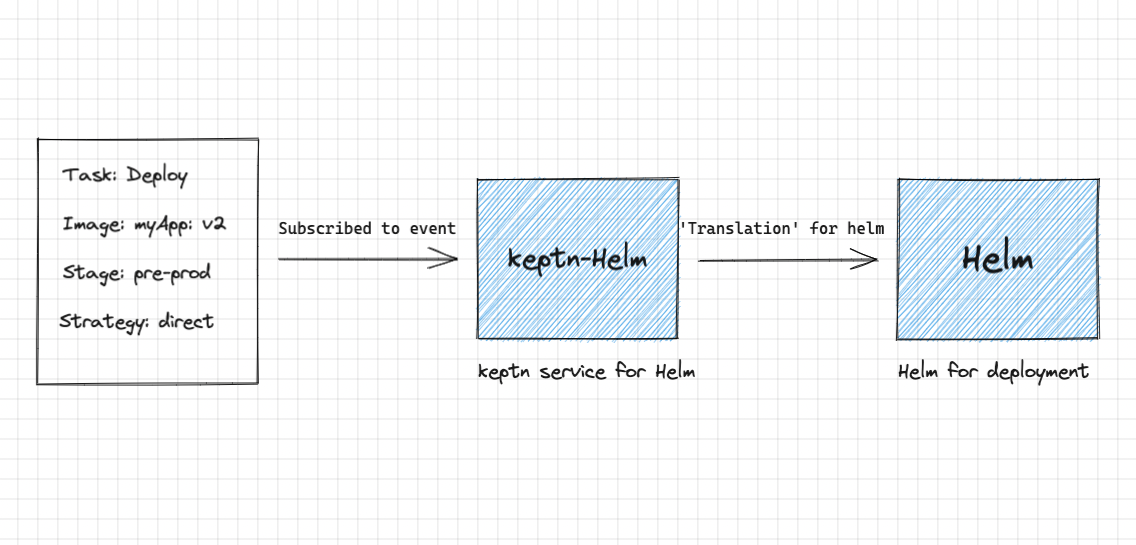
keptn provides services for limited tools for now, but Web hooks can be used to attach almost any tool needed for the task. Meanwhile, the community is working to increase the services.
Now, your tools are separated from the workflow! They look like this. No more integration scripts, just a small shipyard file, used to tell "What to do", Keptn will manage the "How to do".
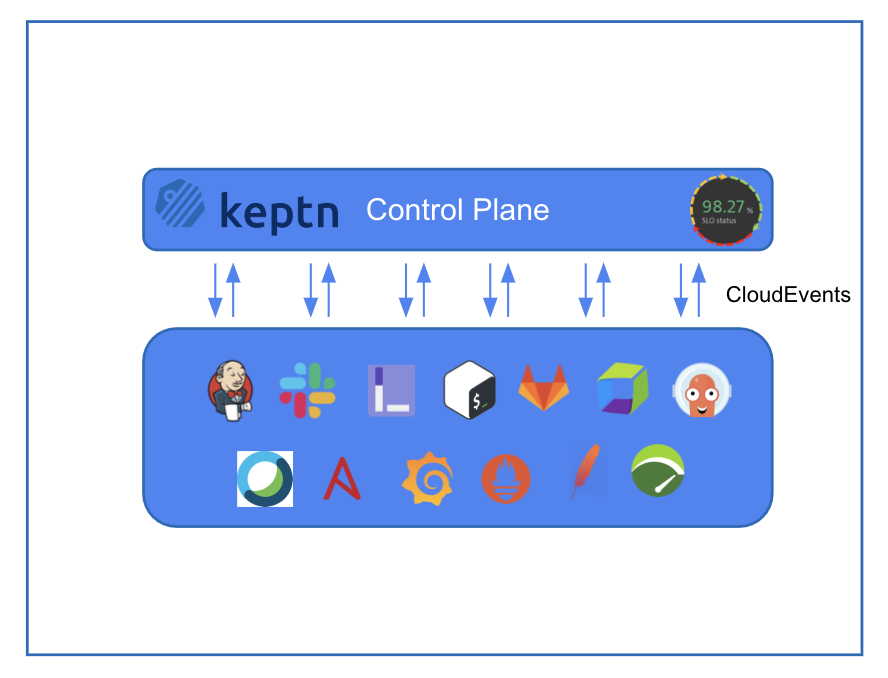
2. Reusable pipelines: #
- As mentioned in the above section, now the tools used don't matter. If you want to change it, just change the tool-specific service.
- Example: if you want to use Dynatrace instead of prometheus, just change the service from prometheus service to Helm, everything else remains the same. it even manages the version difference. There is no script, so nothing really changed. Monitoring will still happen, Dynatrace will do it, instead of Prometheus.
3. Efficient and Asynchronous workflow: #
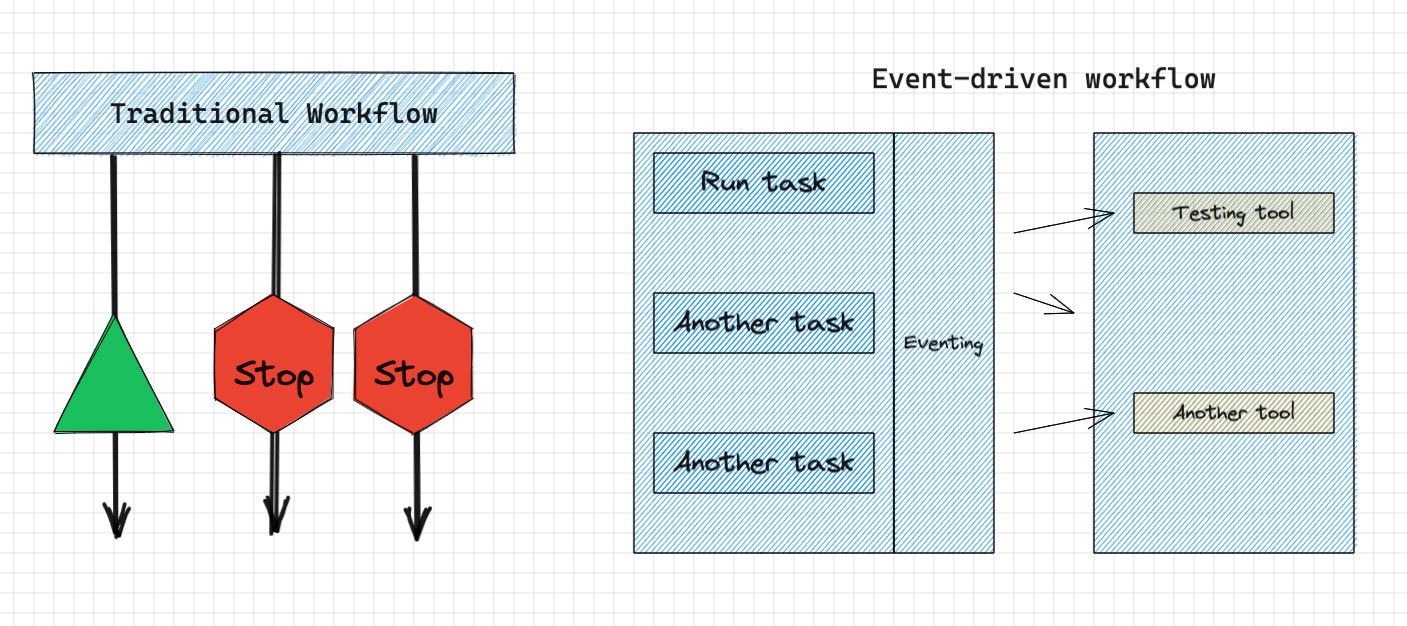
-
As we know that keptn is event-driven. It does not function synchronously as a normal automation script would. Let's take an example.
-
Let's say you just did a Jenkins build, and now it's running a 5 hours long test. While testing happens, other builds and tasks are blocked ! But in case of event-driven workflow, the tasks are independent. The tools start performing the task and keptn triggers the next task. When any of the previous task is completed, it sends back the "completion" message. Similar to how Asynchronous JavaScript works in our modern websites.
4. Validation Gates: #
-
Initially we needed manual approval, that needed comparing the overall performance of the application, deciding if the changes need to be approved or rejected. It takes a lot of time and is prone to error ! Data produced due to the tests, isn't really human friendly as well, it is overkill and finding insights in it takes more time.
-
Now manual process is replaced by keptn's Quality Gates. It works on SRE principles. Keptn has a built-in service for evaluation, The lighthouse service. It compares SLIs with SLOs and decides if the performance is good enough to forward the application to the next stage. There are SLI.yml and SLO.yml files, that contain necessary information.
What are SLIs, SLOs and SLAs ? Here is an image. #
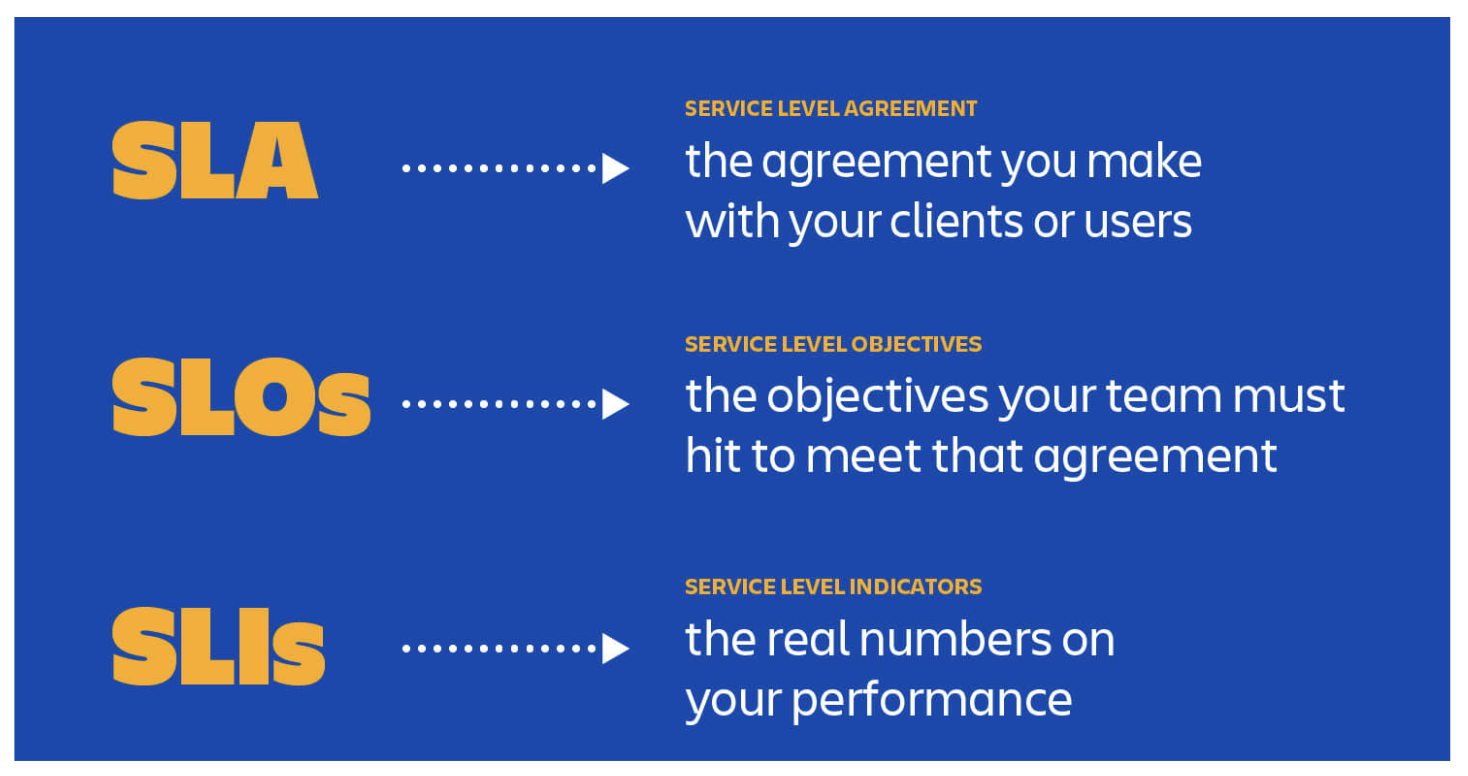
SLIs: Service level indicators, they are collection of metrics, generated by monitoring tools. This tells how the new application performed against the tests.
SLOs: Service level objectives, they are the collections of objectives. How our application should perform.
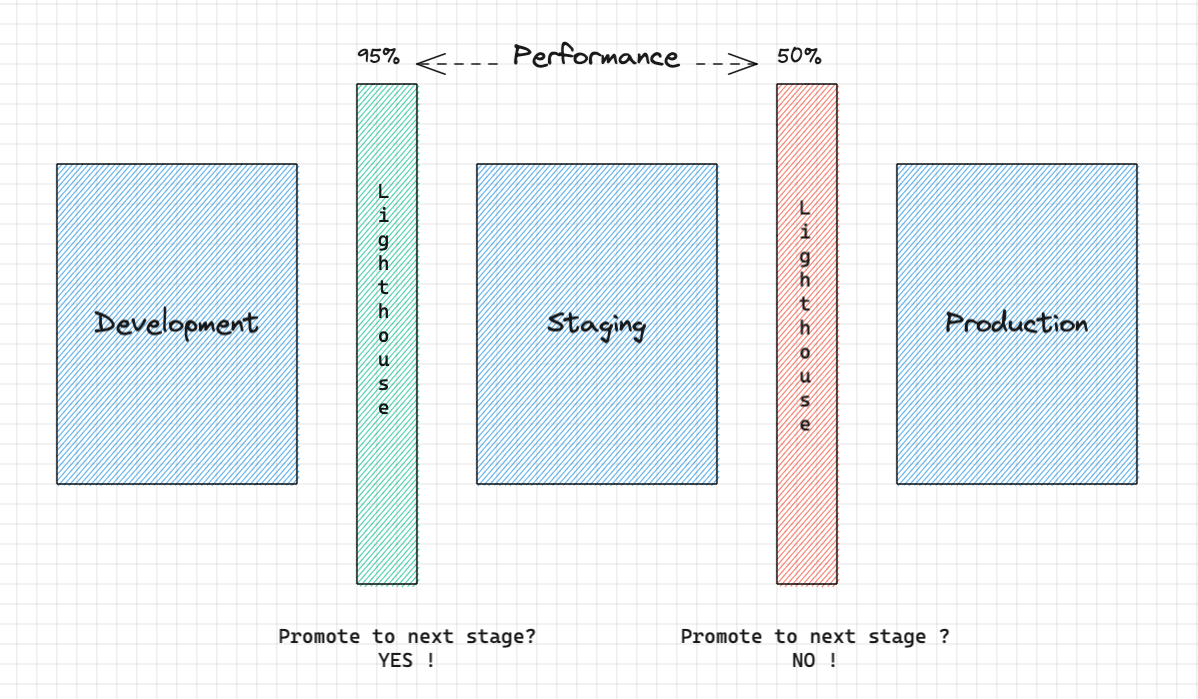
-
So the lighthouse service pulls the performance report of the application. The report is produced by monitoring tools while the application was being tested. Compares them with the SLOs, and finally calculates the score, about how the application performed. Hence, removing the manual aspect of Evaluation. The output is a score, which is sent back to the keptn control plane.
-
Manual as well as Automated approval is possible, just specify it in the shipyard file. So that Keptn knows what needs to be done.
5. Automated Operations: #
-
Let's say the application was finally deployed to production by using one of the method mentioned in the shipyard file. Things are working fine but all of a sudden the containers start crashing or the response time of the application is high now. It is due to the festivals! Your application is being visited more often, the traffic is increasing.
-
Usually a monitoring tool keeps an eye on this and notifies the maintainers if something goes wrong, but it might happen anytime and the maintainers suffer a lot due to this. Maybe the problem was very trivial, but the team had to visit and check. Keptn solves this issue as well via it's "remediation" feature.
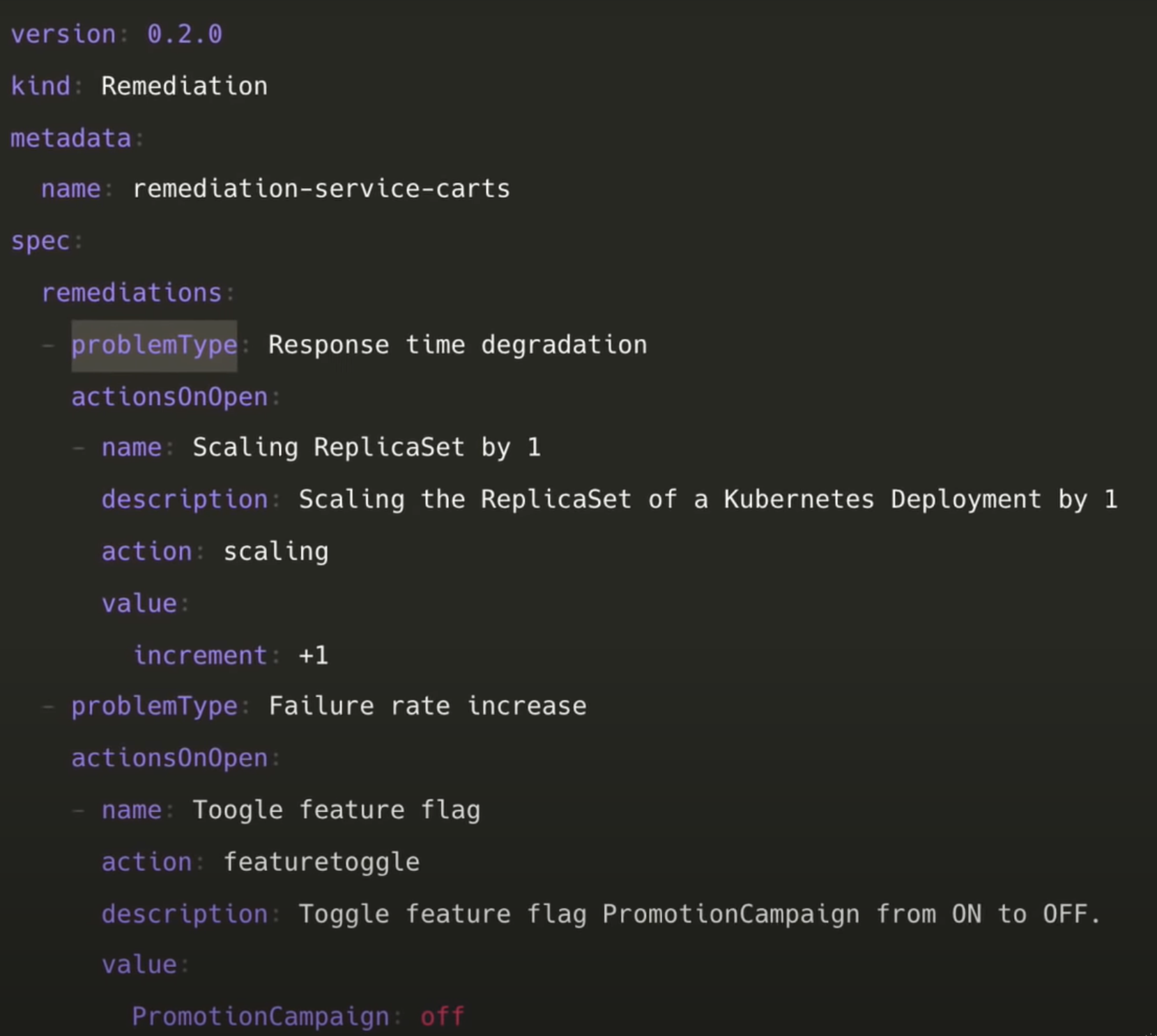
-
Above is a sample remediation sequence. Let's say one of our services start failing, monitoring tools are observing the cluster. Now, instead of directly notifying the maintainers, the tools notify keptn about the problems. Keptn check the remediation sequence and compares the "problemType" mentioned.
-
Let's say our application is facing "Response time degradation", as a remediation measure, Keptn will scale up the application. How ? It will send the task in form of an event, the subscribed tools listen to it and do the task. So, is the issue fixed now?
-
The monitoring tools will watch the cluster for some time, collecting the metrics. After sometime, the Lighthouse service will re-evaluate the performance and respond with a score. If it's good, the issue is fixed without any human interference. Automated Operations !
-
If the issue isn't fixed, the next remediation sequence will run. Removing the feature flag and switching to the previous version of the application. The results will again be evaluated by the lighthouse service.
-
If even after running the remediation sequences, the problem isn't fixed. The maintainers will be informed. And you can see, monitoring and alerting is a core part of Keptn !
Finally, let's see how an entire release cycle with keptn looks like, with an example.
Example release cycle: #
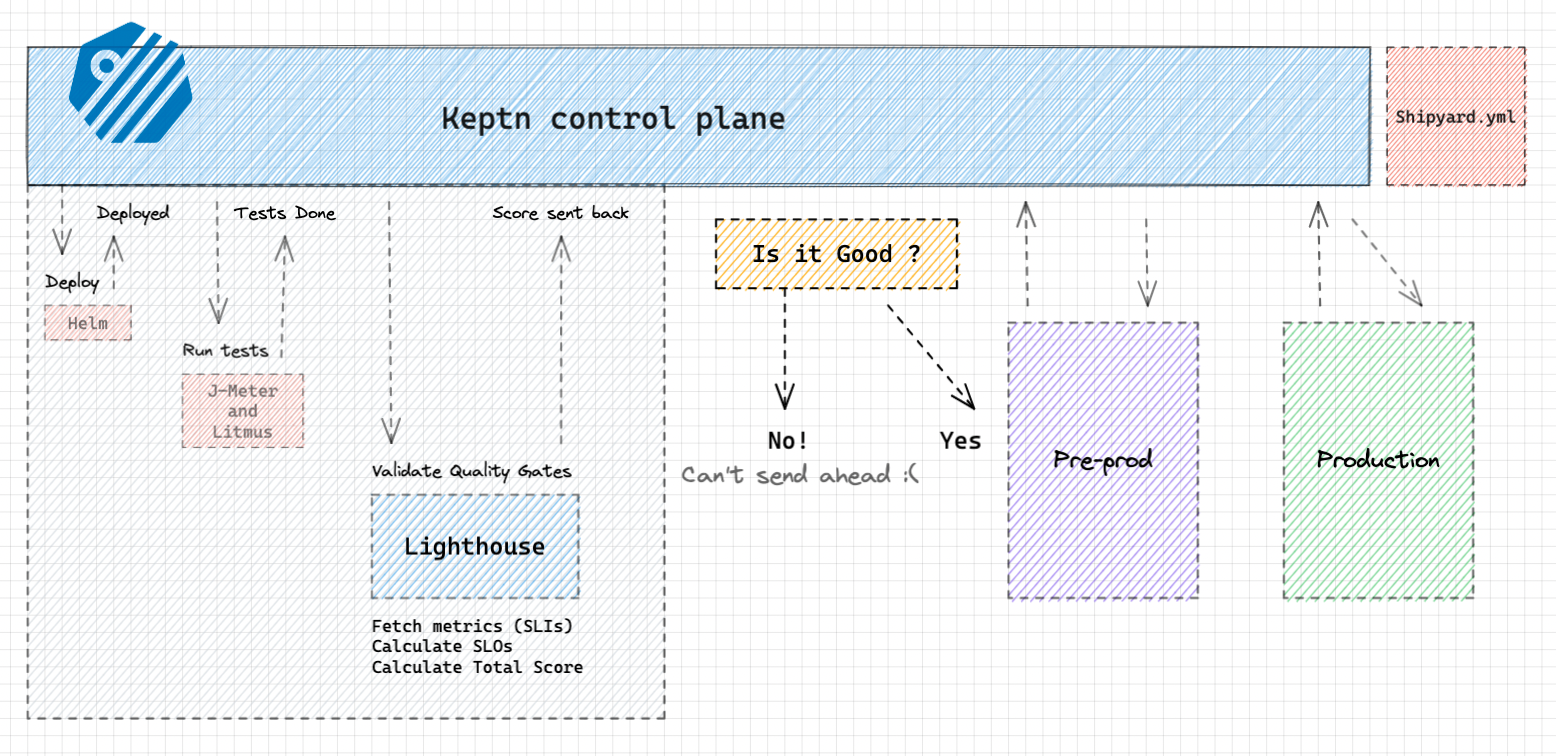
-
The changes in the repository were made, which triggered, let's say, a jenkins build, Test → Build image → Push to registry → Tell Keptn to start multi-stage delivery.
-
Now keptn does its work, in all the stages. Development, pre-production and Production. Therefore, performs "Multi-stage-delivery" of the application from development, all the way up to production ! It follows the GitOps principles. Which is an industry standard, but we will talk about it some other time.
Where does Keptn reside? #
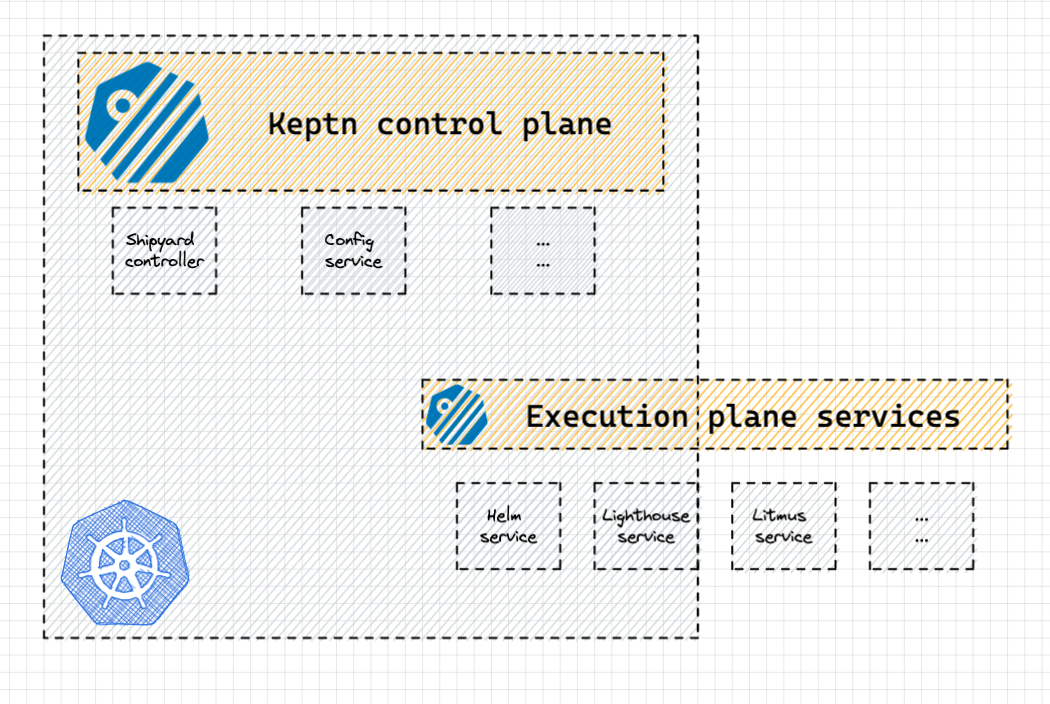
- It resides in your Kubernetes cluster itself ! The control plane, that manages everything Keptn related resided in your cluster, meanwhile the Execution plane services, that provide the functionality, like the Keptn Helm-service can reside inside as well outside the cluster.
This gives enough information about the keptn project to get started. You can learn more via the official documentation. It is a CNCF incubating project, to help the community grow ! Here is a hands-on demo about the project, test it out Killercoda-keptn: end-to-end delivery.
Writing this blog has been an amazing journey for me. It helped me a lot, to learn more about the project. The thoughts behind it are amazing, and it really solves many real world problems. The first step of getting started with contributing to any open source project is getting to know what it does. Join the community, join the conversation and I hope this blog helps you get started with your open source journey :D
The community is very helping, and I look forward to contributing more. keptn project check it out !
Special thanks to @Saiyam Pathak and Nana (TechworldWithNana) for their amazing resources. Helped me a lot in my journey.
I am a student, exploring every day, learning and sharing. I learn about different tools and projects, so that I can provide some value to them. If my blogs help folks to get started with their open source journey, It's a win for everyone ! Here is my twitter/LinkedIn. Let's explore together!
Follow Kubesimplify on Hashnode, Twitter and Linkedin. Join our Discord server to learn with us.
I am a Full stack Software engineer, majoring in Computer science. I have strong foundational skills in multiple domains including Frontend, Backend engineering as well as Kubernetes administration. I am an active Open Source contributor, with contributions in major Open source projects including Cilium, Dapr etc. I also love to build products in general so I am trying out new tech regularly. I am also founder of Senseii, a SaaS product that helps people in their fitness journey by creating workout and meal plans for them. It also helps them follow their plan by regular updates and real time data processing.
Get new posts in your inbox.
Spotted a typo or want to improve this post? Edit on GitHub →