Simplified Introduction To Bacalhau
Bacalhau is an open-source project wherein the existing workflows can be streamlined without rewriting by running Docker containers and Web Assembly (WASM)


On this page (4)
Bacalhau is an open-source project wherein the existing workflows can be streamlined without rewriting by running Docker containers and Web Assembly (WASM) images. This architecture which is referred to as Compute Over Data (CoD) enables users to run compute jobs where the data is generated and stored. Bacalhau platform makes computation secure, fast, and cost-efficient.
The interesting fact is the name “Bacalhau” is derived from the Portuguese word for salted codfish which is a common dish in Portugal.
Features of Bacalhau: #

-
Fast job processing: As Bacalhau supports Docker and WASM, jobs can be easily executed without complex configurations and making any changes to the base code. This helps in orchestrating and distributing workloads easily.
-
Fault Tolerance: If the node fails, Bacalhau automatically finds another node to run the job successfully. It ensures the job is completed even if there are network disruptions.
-
Low cost: Bacalhau utilizes idle computing capacity
-
Secure: Here instead of bringing data over compute, you bring compute over data. This can reduce the leaking of data and more granular permissions to our data.
-
Large-scale data: Bacalhau can run anywhere from low-power edge devices to the largest VMs. You can batch-process petabytes of data.
More info on the project can be found here: https://github.com/bacalhau-project/bacalhau#why-bacalhau
Architecture #
Bacalhau allows decentralized communication as it is a peer-to-peer network of nodes.
Each node in the network has two components: a requester and compute component.

- Requester Component:
The requester node plays a very crucial role in the Bacalhau network as it serves as the main point of contact for the users. It majorly handles requests from users using JSON over HTTP. When a job is submitted to a requester node,
The requester component takes the input of a request, now this request comes from the user via the CLI. Once the request for executing the jobs comes in, the requester node is responsible for broadcasting the job to be executed over the network where all the compute nodes are connected. It is also responsible for effective communication between the nodes on the network.
How this works is that once the job is broadcasted over the network, compute nodes will accept or reject that request. Now, there is only a single requester node for a particular job.
The accepted compute nodes will execute the job and produce a verification proposal, then these proposals will be accepted or rejected, and then the compute nodes will publish the raw results.
- Compute Component:
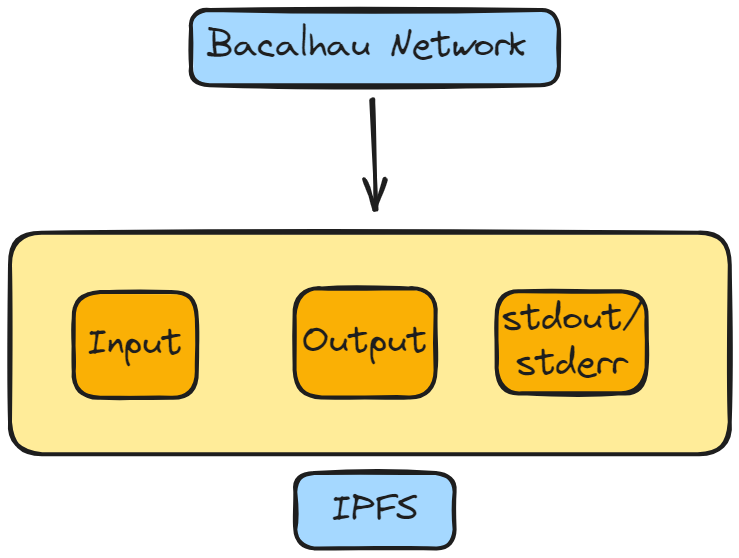
Compute Node is responsible for executing the jobs and producing the results. Once the bid is made by compute node and accepted by the requester node, the compute node runs the job using executors, each of which has its collection of storage providers. Once the executor executes the job, compute node produces a verification proposal. These proposals will either be rejected or accepted, after which compute node produces its raw results via the publisher interface.
- Interface:
The interface handles the distribution, execution, storage, verification, and publishing of jobs. The following are the interfaces:
a. Transport: The transport interface uses a protocol called bprotocol to distribute job messages efficiently to other nodes on the network. It is responsible for sending messages about the jobs that are created and executed to other compute nodes. It ensures that the messages are delivered to the correct node without causing network congestion.
b. Executor: The executor is mainly responsible for two actions that are running the job and the other one is to present the storage volumes in a format that is suitable for the executor.
When the job is completed, the executor will merge the stdout, stderr, and named output volumes into a results folder. This results folder is used to generate a verification proposal that is sent to the requester.
c. Storage Provider: There are multiple execution platforms like Docker and WASM and then the executor will select the appropriate storage provider based on this implementation. So, there will be multiple storage providers present in the network.
d. Verifier: It checks the results produced by the executor against results produced by other nodes and transports those results back to the requester node. Both compute and requester node have verifier component. The compute node verifier produces a verification proposal based on having run the job, while the requester node verifier collates the proposals from various compute nodes.
e. Publisher: It publishes the final result of a job to a public location where users can access them. The default publisher used is Estuary and if Estuary is used as the publisher, the results will also be stored on Filecoin. The published results are stored with a unique content identifier (CID).
Installation and Demo #
Now that we know what Bacalhau is, and how it works, Let's try to install the CLIand in future blogs, we will start looking into more deep dive demos.
I am using play with docker to install bacalhau.
docker pull ghcr.io/bacalhau-project/bacalhau:latest

docker run ghcr.io/bacalhau-project/bacalhau:latest
To verify and check the version of Balcalhau:
docker run -it ghcr.io/bacalhau-project/bacalhau:latest version

You can also do a curl command to download the cli binary and use it.
curl -sL https://get.bacalhau.org/install.sh | bashRunning hello world(as usual, nothing is complete without a hello world)
docker run -t ghcr.io/bacalhau-project/bacalhau:latest docker run --id-only --wait ubuntu:latest -- sh -c 'uname -a && echo
"Hello from Saloni Bacalhau!"'
095be3fd-095f-4c55-bacf-19578dc72580As you can see above you have the job ID that will be used to fetch the status, this is actually hitting the public network to execute the job.
Export the Job ID
export JOB_ID=095be3fd
$ docker run -t ghcr.io/bacalhau-project/bacalhau:latest list --id-filter ${JOB_ID}
CREATED ID JOB STATE VERIFIED PUBLISHED
18:59:25 095be3fd Docker ubuntu:latest... Completed ipfs://Qmex4tjNsxY8J...so our job has successfully been completed and we need to download the results which we can do by running the bacalhau get command.
$ bacalhau get $JOB_ID
Fetching results of job '095be3fd'...
Computed default go-libp2p Resource Manager limits based on:
- 'Swarm.ResourceMgr.MaxMemory': "17 GB"
- 'Swarm.ResourceMgr.MaxFileDescriptors': 524288
Theses can be inspected with 'ipfs swarm resources'.
2023/07/09 19:17:00 failed to sufficiently increase receive buffer size (was: 208 kiB, wanted: 2048 kiB, got: 416 kiB). See https://github.com/quic-go/quic-go/wiki/UDP-Receive-Buffer-Size for details.
Results for job '095be3fd' have been written to...
/tmp/job-095be3fd
2023/07/09 19:17:01 CleanupManager.fnsMutex violation CRITICAL section took 22.293641ms 22293641 (threshold 10ms)The output has been written to the /tmp directory. Finally, it's time to verify the results.
cat /tmp/job-095be3fd/stdout
Linux fadcacb48980 5.19.0-1026-gcp #28~22.04.1-Ubuntu SMP Tue Jun 6 07:24:26 UTC 2023 x86_64 x86_64 x86_64 GNU/Linux
Hello from Saloni Bacalhau!Conclusion #
In this blog, we learned about the basics of Bacalhau, what the project is all about, and how it works using the decentralized network of compute nodes to execute the jobs and publish the results. In the next part, we will go through a deep dive demo where we will try to execute the Job.
Share the blog if you learned about Bacalhau and I will post the next deep dive version soon.
Follow Kubesimplify on Hashnode, Twitter and LinkedIn. Join our Discord server to learn with us.
Get new posts in your inbox.
Spotted a typo or want to improve this post? Edit on GitHub →