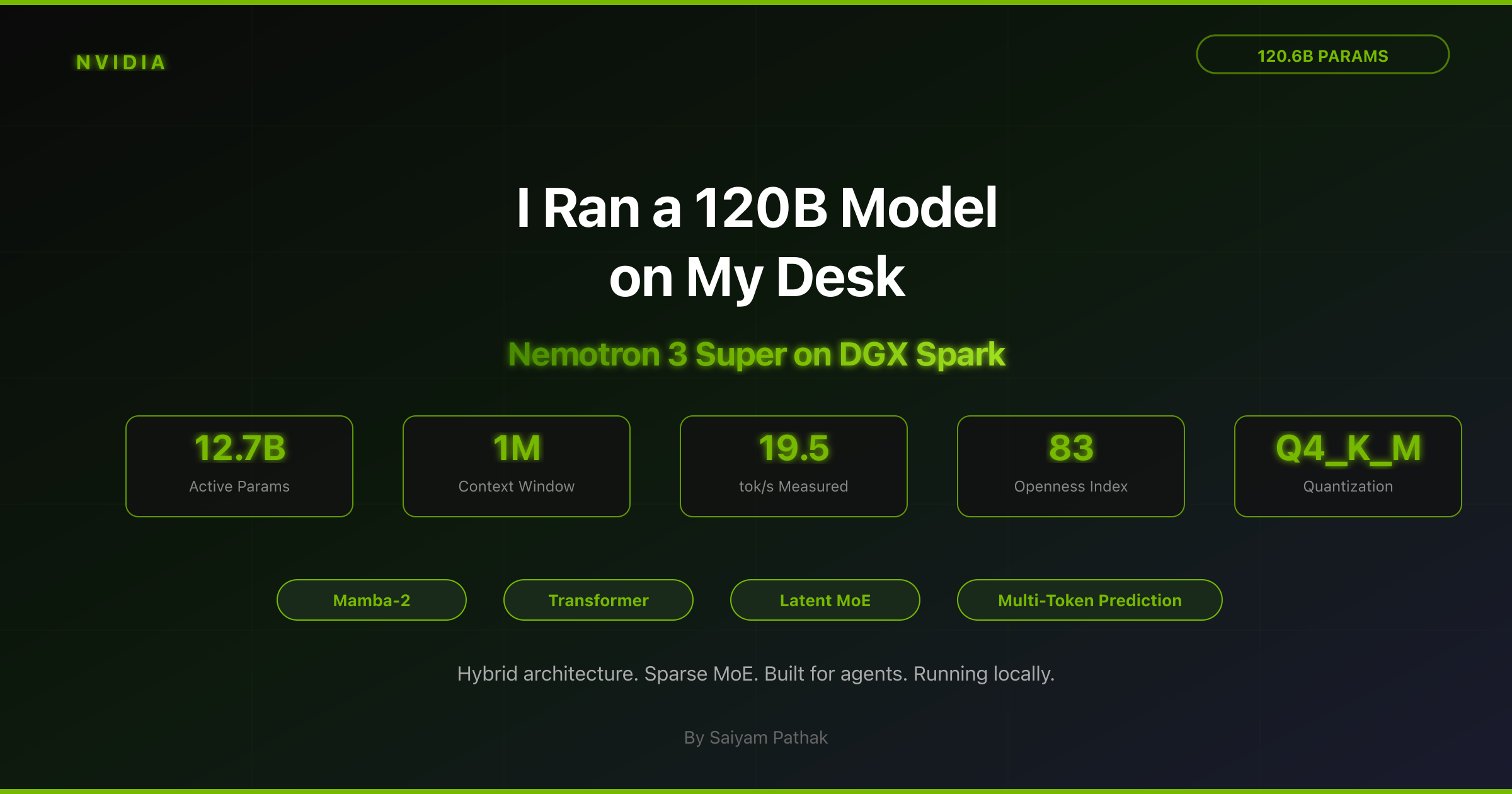
Here's What I Learned About Nemotron 3 Super -I Ran a 120B Parameter Model on Nvidia DGX Spark
Understand everything about Nvidia DGX spark along with hands on and benchmarks.

On this page (14)
- The Headline Numbers (And Why They’re Misleading)
- Three Architectures in a Trenchcoat
- Mamba-2: The Workhorse
- Transformer Attention: The Precision Tool
- The KV Cache Payoff
- Latent MoE: Getting 4x More Experts for Free
- Multi-Token Prediction: Built-In Speculative Decoding
- How It Was Trained: The Three-Phase Pipeline
- Why NVIDIA Built This for Agents
- Running It: Three Paths from Zero to Inference
- The DGX Spark: Quick Hardware Context
- Putting It in Context: How Nemotron 3 Super Compares
- What I’d Actually Use This For
- The Bigger Picture
There’s a moment when you’re watching a model load into memory. The progress bar is filling up to 87 gigabytes and it hits you. You’re about to talk to something that has 120 billion parameters. Not through an API. Not in the cloud. On a box the size of a sandwich sitting next to your keyboard.
That’s what running NVIDIA’s Nemotron 3 Super on the DGX Spark feels like. After spending time with it, I think this model needs more attention than it’s getting. Not because of one benchmark number, but because of the engineering choices behind it. These choices show you exactly where AI inference is going.
Let me walk you through what I found.
The Headline Numbers (And Why They’re Misleading) #
When NVIDIA drops a model, they lead with the big stats: 120 billion parameters, 1 million token context, 5x throughput. These numbers are real, but they hide the real story.
The number that actually matters is 12.7 billion. That’s how many parameters fire per token. Out of 120.6 billion total, only about a tenth light up for any given input. The rest sit there, waiting until the right token needs their skill.
This roughly 10:1 ratio is the whole story. It’s why the model runs on desktop hardware. It’s why it’s fast. It’s why NVIDIA built it this way. Everything else follows from this one design choice.
The second thing that matters is the layer mix. The model has 88 layers total. Most of them are Mamba-2 layers. This is a completely different architecture from transformers and it doesn’t need to store growing key-value caches. Only a small number are traditional transformer attention layers. NVIDIA interleaves them in a repeating pattern: groups of Mamba-2 blocks paired with Latent MoE layers, with attention layers placed at key depths. We’ll come back to why this split is so important.
Three Architectures in a Trenchcoat #
Nemotron 3 Super isn’t one architecture. It’s three, stacked together so each one does what it’s best at. Once you get this stack, you get why the model works the way it does.

Mamba-2: The Workhorse #
The majority of the 88 layers are Mamba-2 blocks. Mamba is a state-space model. Think of it like a recurrent architecture that keeps a compact, fixed-size state and updates it as each new token comes in.
The key thing: Mamba runs in linear time. Double the sequence length, you roughly double the compute. Compare that with transformer attention, where doubling the sequence quadruples the compute.
This is why Nemotron 3 Super can actually deliver a 1-million-token context window in practice. With most layers being Mamba, the bulk of the model doesn’t care how long your prompt is. Compute grows linearly, and memory doesn’t grow at all. Mamba’s state stays the same size no matter the sequence length.
Transformer Attention: The Precision Tool #
A small number of layers in the stack are traditional transformer attention layers, using Grouped Query Attention with 32 query heads, 2 KV heads, and a head dimension of 128. These are confirmed specs from the technical report.
Why keep any attention at all? Because Mamba has a known gap. It struggles with precise associative recall, like connecting a specific detail from position 1,000 with something at position 500,000. The fixed-size state means some info gets compressed away over very long sequences.
NVIDIA’s fix: place attention layers at carefully chosen depths through the 88-layer stack. They act like precision tools, handling the long-range connections that Mamba would miss, while Mamba does everything else fast.
The result: the vast majority of the model’s compute happens in linear time. Quadratic attention is used only where it’s needed.
The KV Cache Payoff #
This design has a huge side effect that matters a lot for hardware like the DGX Spark.
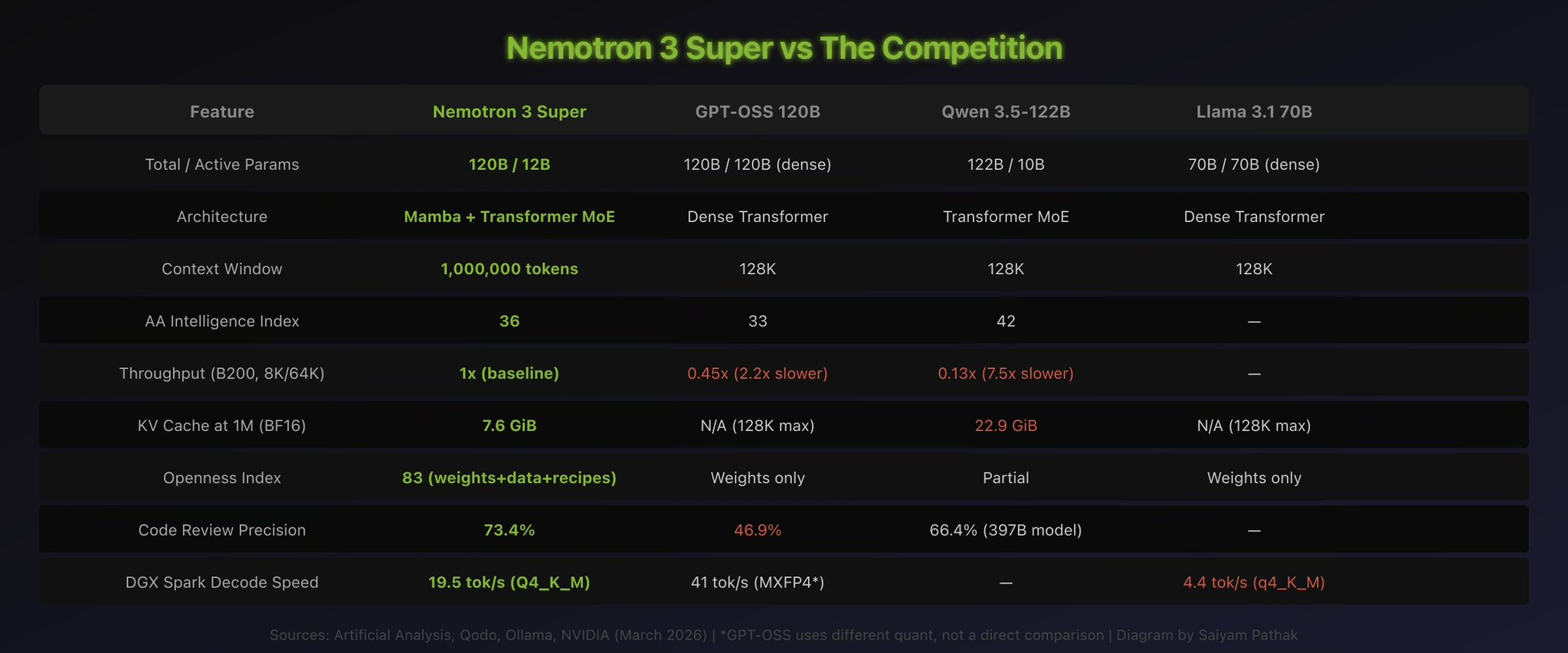
In a transformer, the KV cache grows with sequence length. Every attention layer stores key and value tensors for every token it has seen. For a model like Qwen 3.5-122B with 12 full attention layers, head dimension 256, and 2 KV heads, that adds up to about 22.9 GiB at 1 million tokens in BF16. (The math: 12 layers x 2 KV heads x 256 dim x 2 bytes x 2 for K+V x 1M tokens.)
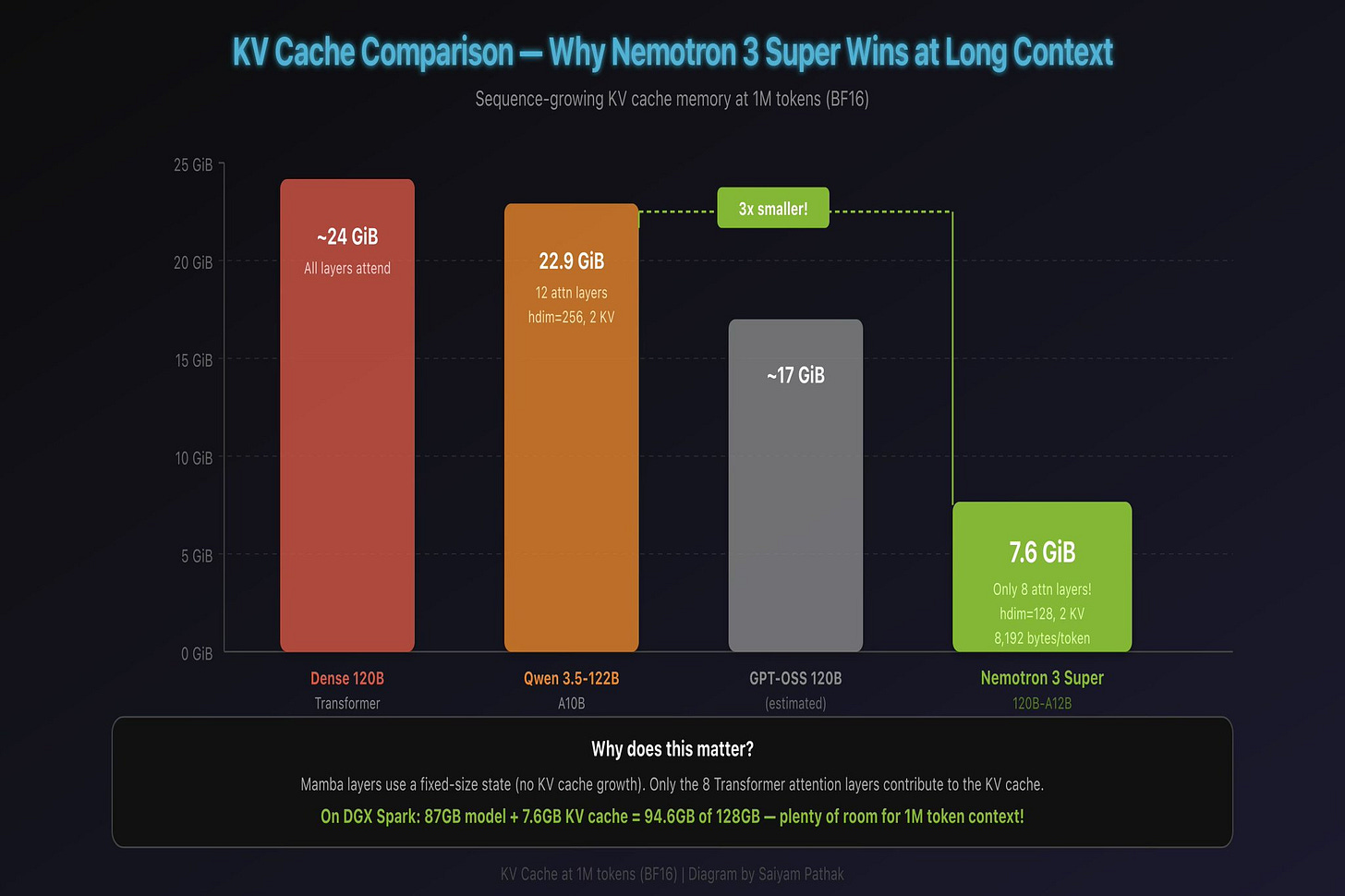
Nemotron 3 Super has far fewer attention layers, each with head dimension 128 and 2 KV heads. Because Mamba layers use a fixed-size state (no KV cache growth), only the attention layers add to the KV cache. The bottom line: the KV cache is roughly 3x smaller than Qwen’s at the same context length. On the DGX Spark’s 128 GB of unified memory, you load the 87 GB model, add a relatively small KV cache even at very long contexts, and you still have plenty of room to spare.
For practical purposes, the KV cache almost doesn’t matter with this model.
Latent MoE: Getting 4x More Experts for Free #
The Mixture of Experts layer is where things get really clever.
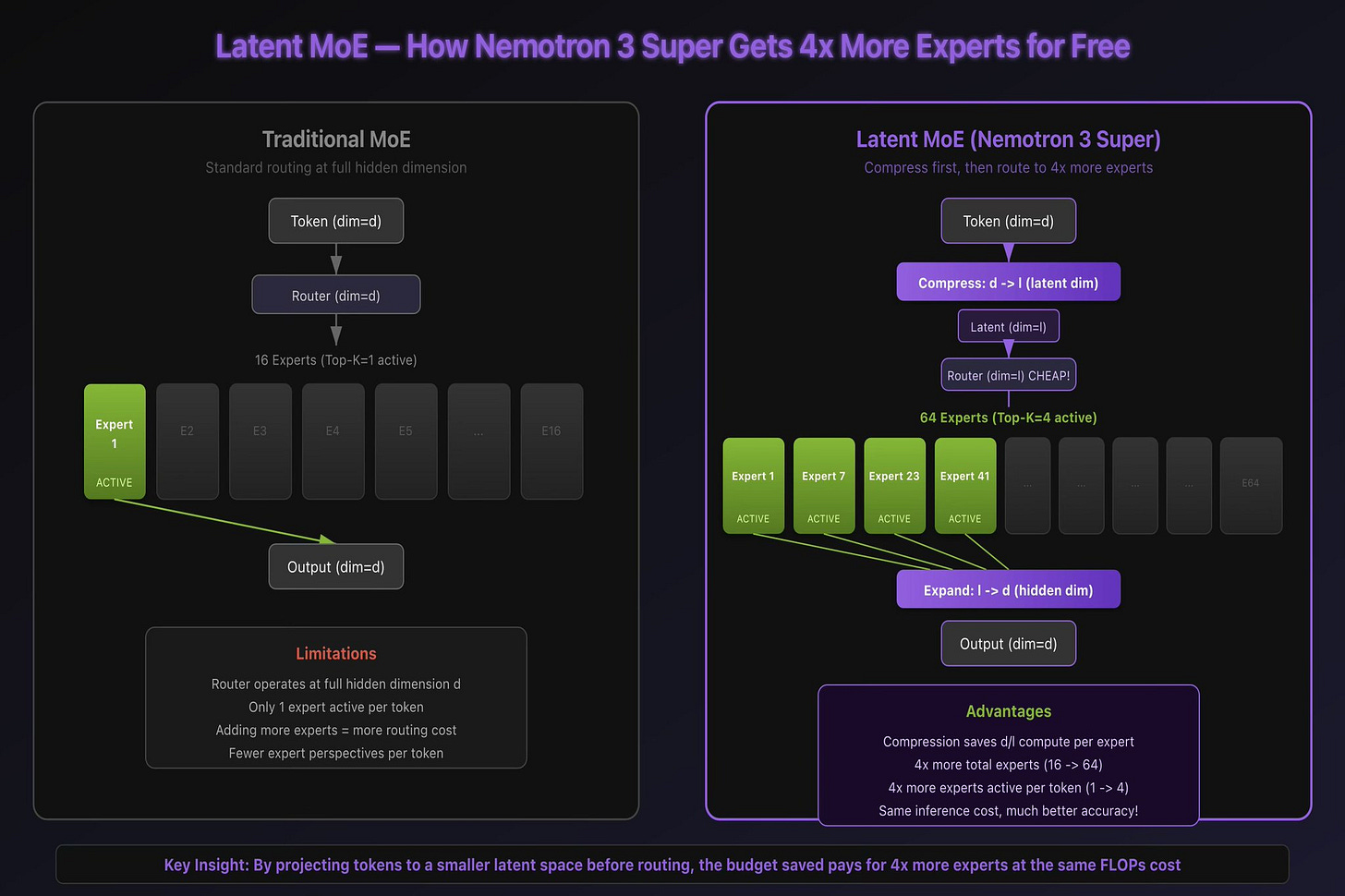
In a standard MoE, each token is routed to one or two “expert” sub-networks from a larger pool. The idea is simple: different experts specialize in different things, and the router learns which expert to call for each token.
The problem is cost. Routing happens at the model’s full hidden dimension, and each expert operates at that same dimension. If you want more experts (for better specialization), routing gets more expensive. If you want to activate more experts per token (for better accuracy), inference gets slower.
Latent MoE solves this with a compression trick. Before routing, token embeddings are projected from the full hidden dimension down to a smaller latent dimension. The router operates in this compressed space, which is much cheaper. Experts also operate on the compressed representations.
The compute you save on compression doesn’t disappear. It gets reinvested. NVIDIA uses it to increase both the total number of experts and the number of experts active per token by the same factor. The result: 4x more experts consulted per token, at approximately the same inference cost as a standard MoE with fewer experts.
Each token effectively gets a committee of 4 specialists deliberating instead of a single expert making a snap judgment. The accuracy improvement is significant, and you don’t pay for it in latency.
Multi-Token Prediction: Built-In Speculative Decoding #
Standard language models predict one token at a time. Generate position N, feed it back in, generate position N+1, repeat. This sequential nature is the fundamental bottleneck in text generation speed.
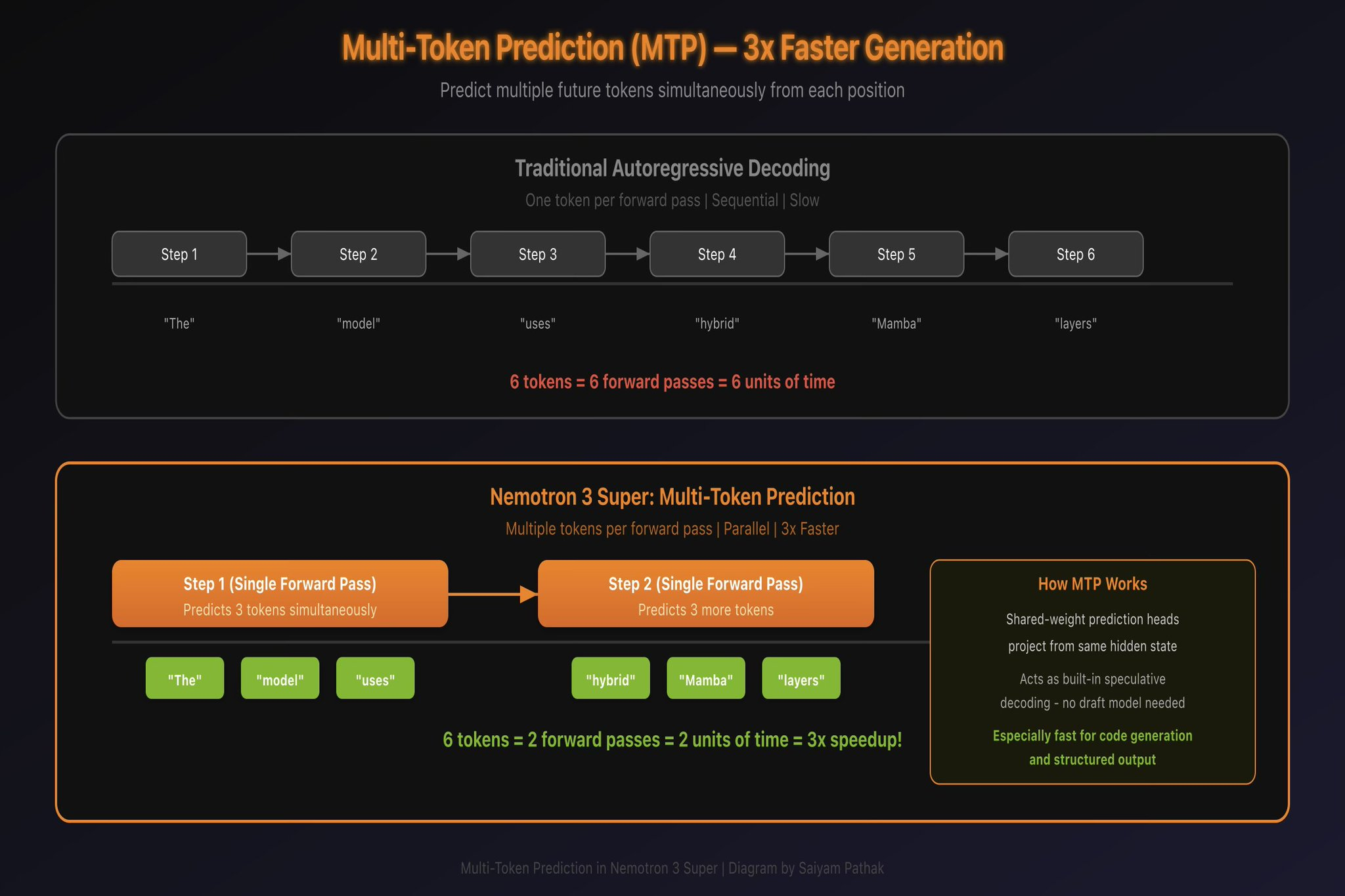
Nemotron 3 Super predicts multiple future tokens from each position simultaneously. The model has shared-weight prediction heads that project from the same internal representation to predict not just the next token, but several tokens ahead.
This serves two purposes. During training, it forces the model to learn longer-range dependencies. You can’t predict three tokens ahead without understanding the broader context. This makes the model smarter.
During inference, it works like built-in speculative decoding. Instead of generating one token per forward pass, the model proposes multiple tokens, verifies them, and keeps the correct ones. For structured output like code and tool calls, where the next few tokens are often very predictable, NVIDIA reports up to 3x wall-clock speedup. General chat won’t see the full 3x, but code generation benefits a lot.
The nice thing: you don’t need a separate draft model. The speculation is built right into the model.
How It Was Trained: The Three-Phase Pipeline #
This is where NVIDIA’s openness really shines. They didn’t just release weights. They published the complete methodology, and the numbers are big.

Phase 1: Pretraining. 25 trillion tokens total (10 trillion unique), plus 10 billion additional tokens focused specifically on reasoning, plus 15 million coding problems. The majority of compute ran in NVFP4, which is NVIDIA’s native 4-bit floating point format. This is unusual and important: most models train in higher precision and quantize down later, losing accuracy. Nemotron 3 Super was born in FP4.
Phase 2: Supervised Fine-Tuning. 7 million carefully selected samples from a corpus of 40 million. Coverage spans reasoning, instruction following, coding, safety, and critically, multi-step agent task completion. This phase is where the model learns to be useful, not just knowledgeable.
Phase 3: Reinforcement Learning. 1.2 million environment rollouts across 21 different configurations, using NeMo Gym and NeMo RL frameworks with 37 datasets. This is where the model learns to reason through complex, multi-step problems. This is the kind of thinking that makes it useful as an autonomous agent.
NVIDIA released around 10 of the pretraining datasets publicly, 15 RL training environments, and about 10 of the 37 RL datasets, along with complete training recipes. The Artificial Analysis Openness Index scored this release at 83 out of 100. Only two research labs (Ai2 and MBZUAI) score higher, and their models aren’t anywhere near this performance level.
This kind of transparency is new for a model this good. With enough compute, you could follow their recipe and reproduce the training run yourself.
Why NVIDIA Built This for Agents #
The model wasn’t designed for chatbots. Every architectural decision points toward one use case: long-running autonomous agents. The 1M context, the sparse activation, the MoE efficiency. All of it.

When you run a multi-agent system, token consumption explodes. Each agent interaction requires sending the full conversation history, tool outputs, intermediate reasoning steps, and results from other agents. NVIDIA’s numbers suggest multi-agent workflows generate up to 15x more tokens than standard chat.
This creates two problems that kill most models:
Context overflow. At 128K tokens, even large models run out of context in extended agent sessions. The agent either loses early context (and the original goal with it), or you implement complex summarization/RAG schemes that lose fidelity. Nemotron 3 Super’s million-token window means the agent can hold the entire workflow state. Every tool call, every intermediate result, every reasoning step stays in memory without ever truncating.
The cost of thinking. Agents need to reason at every step. If each reasoning call costs as much as a full 120B forward pass, running thousands of agent subtasks gets very expensive very fast. With only 12B active parameters, each call through Nemotron 3 Super costs a fraction of what a dense 120B model would. You get the intelligence of a large model with the economics of a small one.
The benchmarks back this up. On PinchBench, which tests models as actual coding agents (not just answering coding questions), it scores 85.6%. That’s the best open model out there. On DeepResearch Bench, which tests multi-step research over large document sets, NVIDIA’s AI-Q multi-agent system took the number one position. AI-Q is built on top of a fine-tuned Nemotron 3 Super. Worth noting: AI-Q is a full multi-agent system with orchestrator, planner, and researcher sub-agents. It’s not just the base model running solo. But Nemotron 3 Super is the reasoning engine at its core.
Why Sparse MoE is Perfect for the DGX Spark
Here’s something that sounds wrong: on the DGX Spark, a 120B MoE model runs way faster than a smaller 70B dense model. The bigger model is faster. How?

Running It: Three Paths from Zero to Inference #
I tested three ways to get Nemotron 3 Super running on the DGX Spark. Here they are, from simplest to most configurable.
Path 1: Ollama (Two Commands)
The fastest possible path. If Ollama is installed on your Spark (it comes pre-installed on DGX OS):
ollama pull nemotron-3-super
ollama run nemotron-3-supersaiyam@spark-5385:~$ ollama pull nemotron-3-super
pulling manifest
pulling 0fc53cc990a2: 100% ▕███████████████████████████████████████████████████████████████████████████████████████▏ 86 GB
pulling d02d998e5ae6: 100% ▕███████████████████████████████████████████████████████████████████████████████████████▏ 23 KB
pulling 02897ca0d6a3: 100% ▕███████████████████████████████████████████████████████████████████████████████████████▏ 31 B
pulling 9c35241878aa: 100% ▕███████████████████████████████████████████████████████████████████████████████████████▏ 509 B
verifying sha256 digest
writing manifest
success
saiyam@spark-5385:~$ ollama list
NAME ID SIZE MODIFIED
nemotron-3-super:latest 95acc78b3ffd 86 GB Less than a second ago
qwen3.5:35b-a3b 3460ffeede54 23 GB 5 days ago
saiyam@spark-5385:~$ ollama run nemotron-3-super --verbose "Explain the difference between Mamba and Transformer architectures like I'm a DevOps engineer who has never worked with ML."ollama show nemotron-3-super
Model
architecture nemotron_h_moe
parameters 123.6B
context length 262144
embedding length 4096
quantization Q4_K_M
requires 0.17.1
Capabilities
completion
tools
thinking
Parameters
temperature 1
top_p 0.95
License
NVIDIA Software and Model Evaluation License
IMPORTANT NOTICE – PLEASE READ AND AGREE BEFORE USING THE NVIDIA LICENSED MATERIALS.
... Real performance on DGX Spark:
prompt eval rate: 3.51 tokens/s
eval rate: 19.50 tokens/s
eval count: 2504 tokens
total duration: 2m56sPath 2: llama.cpp from Source (Full Control)
If you want more control over context sizes, quantization, and API serving, you can build llama.cpp from source and run the GGUF model directly. Unsloth has a detailed guide for this: Unsloth Nemotron 3 Super Guide
The key things to know for DGX Spark:
-
When building llama.cpp, use -DCMAKE_CUDA_ARCHITECTURES=”121” for the GB10 chip. Without this you’ll fall back to CPU inference.
-
The GGUF files are at unsloth/NVIDIA-Nemotron-3-Super-120B-A12B-GGUF on Hugging Face.
-
NVIDIA recommends temperature 1.0 for general chat, and 0.6 with top_p 0.95 for tool calling.
-
Set --ctx-size based on your available memory. On DGX Spark, 16384 to 262144 is practical. Setting it to 1M may trigger CUDA OOM.
-
llama-server gives you an OpenAI-compatible API, so VS Code Continue, LangChain, CrewAI, Open WebUI all just work.
The DGX Spark: Quick Hardware Context #
For readers unfamiliar with the hardware, the DGX Spark is NVIDIA’s desktop AI computer. The relevant specs:
-
Chip: GB10 Grace Blackwell Superchip
-
Memory: 128 GB unified LPDDR5x (shared CPU/GPU, 273 GB/s)
-
GPU: 6,144 CUDA cores, 5th-gen Tensor Cores, 1 PFLOP FP4 sparse
-
CPU: 20-core ARM (10x Cortex-X925 + 10x Cortex-A725)
-
Size: 150mm x 150mm x 50mm, 1.2 kg
-
Power: 240W
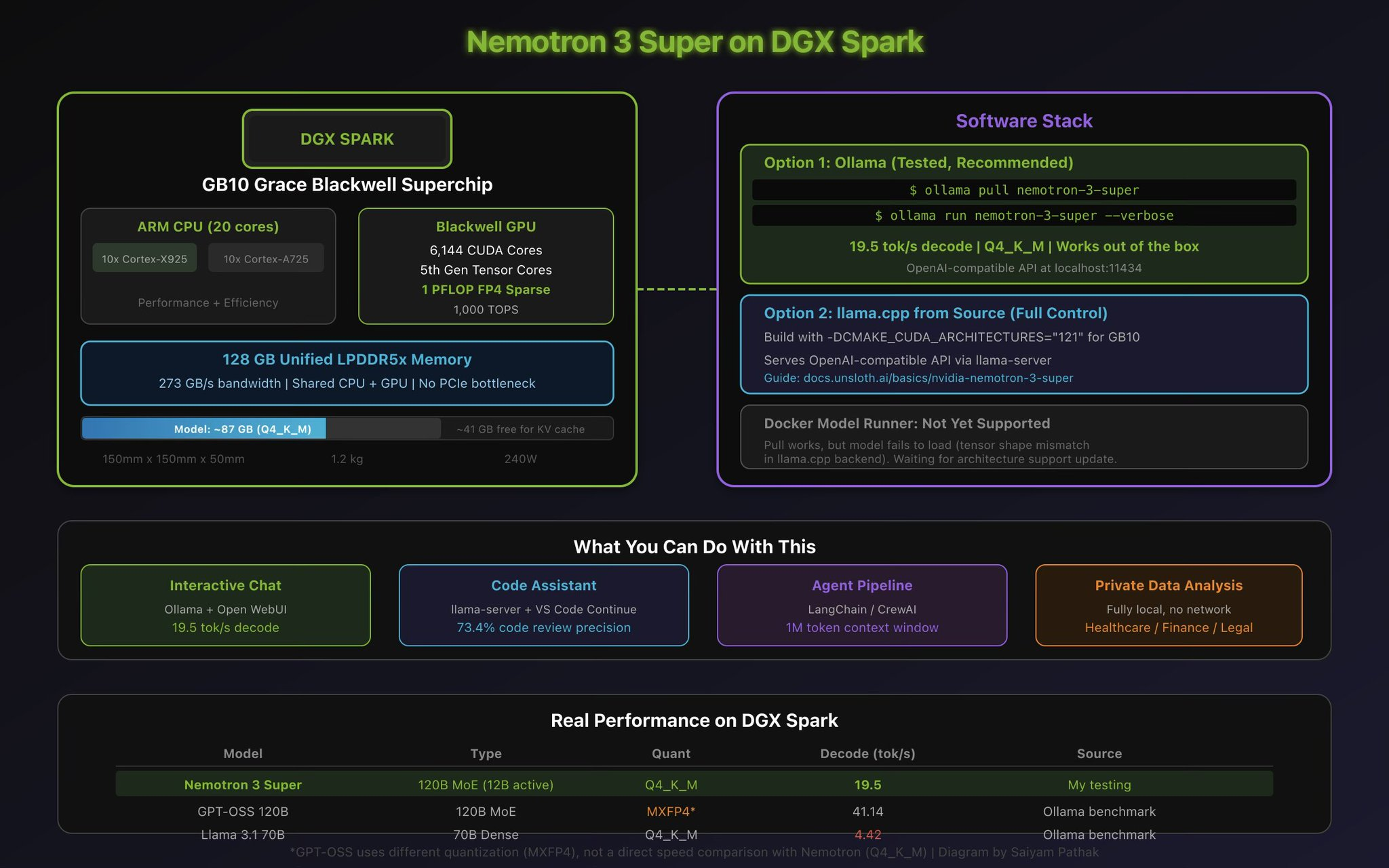
The unified memory is the key. Unlike a discrete GPU where you’re limited by VRAM (24 GB on an RTX 4090, 32 GB on an RTX 5090), the DGX Spark’s 128 GB is coherently shared between CPU and GPU with no PCIe bottleneck. The full 87 GB model lives in one address space.
NVIDIA rates it for models up to 200 billion parameters on a single unit, or 405 billion on two connected Sparks.
Putting It in Context: How Nemotron 3 Super Compares #
Here’s the honest comparison against peers, based on published third-party benchmarks:
What I’d Actually Use This For #
After spending time with the model, here’s where I see genuine value in the Nemotron + DGX Spark combination:
Openclaw - I am going to put this as the model for openclaw too which is already running on my machine.
Private data analysis. If you work in healthcare, finance, legal, or defense, some data simply cannot leave your building. No cloud provider promise changes the rules. A local model that never touches a network is the only option for these workloads.
Code review and analysis. 73.4% precision on Qodo’s code review benchmark means about three out of four issues it flags are real. That’s useful enough for a local code review helper, especially when you’re working on code you can’t send to an external API.
Long-document reasoning. The million-token context with a tiny KV cache means you can load entire codebases, spec documents, or stacks of research papers and ask questions across everything. No chunking, no RAG pipeline needed. Just load it all and ask.
Where I wouldn’t use it: production serving at scale, real-time latency-critical applications, or model training. The DGX Spark is an inference machine, not a training rig.
The Bigger Picture #
Nemotron 3 Super is interesting as a model, but it’s even more interesting as a strategy.
NVIDIA makes the chips (GB10, B200), the inference runtime (NIM, TensorRT-LLM), the training framework (NeMo), and now the models (Nemotron). They’ve released the model, the data, and the recipes. Everything except the hardware to train on.
That’s the play. The more developers build on Nemotron, the more they need NVIDIA hardware. The openness isn’t charity. It’s ecosystem building.
But for us as practitioners, the result is clearly good. We get a top-tier model with full training transparency, running on hardware we can put on a desk. The hybrid Mamba-Transformer architecture with Latent MoE and multi-token prediction isn’t just a research paper. It’s a practical solution for running large models on limited hardware.
NVIDIA has confirmed that Ultra, the bigger sibling at roughly 500 billion parameters, is coming. If Super at 120B is this capable, Ultra will be worth watching closely.
Sources:
-
Artificial Analysis: Nemotron 3 Super — The New Leader in Open Intelligence
-
My own testing on DGX Spark — 19.5 tok/s (Q4_K_M, Ollama), prompt eval 3.51 tok/s
Saiyam is working as Head of DevRel at vCluster Labs. He is the founder of Kubesimplify, focusing on simplifying cloud-native & AI infrastructure. He is KubeCon Co-chair and has worked on many facets of Kubernetes, including machine learning platforms, scaling, multi-cloud, & managed Kubernetes services. When not coding, Saiyam contributes to the community by writing blogs and organizing local meetups for Kubernetes and CNCF. He is also a CNCF TAG OpsRes Chair & can be reached on Twitter @saiyampathak.
Get new posts in your inbox.
Spotted a typo or want to improve this post? Edit on GitHub →
Discussion
Related posts
nvidia
Day 5: Local LLM Inference Engines, Wrappers, and What to Pick
56 min read
nvidia
Day 4: Quantization Demystified. BF16, FP8, NVFP4, MXFP4, INT4, GGUF, and Why It All Matters
28 min read
nvidia
Day 3: The DGX Spark Unpacked. GB10, Unified Memory, sm_121, and the One Reason This Hardware Exists
19 min read