Topic
local-ai
7 articles

Day 5: Local LLM Inference Engines, Wrappers, and What to Pick
A beginner-friendly guide to local LLM inference, with the same Qwen model tested through Ollama, llama.cpp, Docker Model Runner, vLLM, SGLang, and TensorRT-LLM on NVIDIA DGX Spark.


Day 4: Quantization Demystified. BF16, FP8, NVFP4, MXFP4, INT4, GGUF, and Why It All Matters
A practical, beginner-friendly guide to BF16, FP8, NVFP4, MXFP4, INT4, and GGUF Q4_K_M on NVIDIA DGX Spark. Bytes per parameter, quality vs size, and which format to pick when.
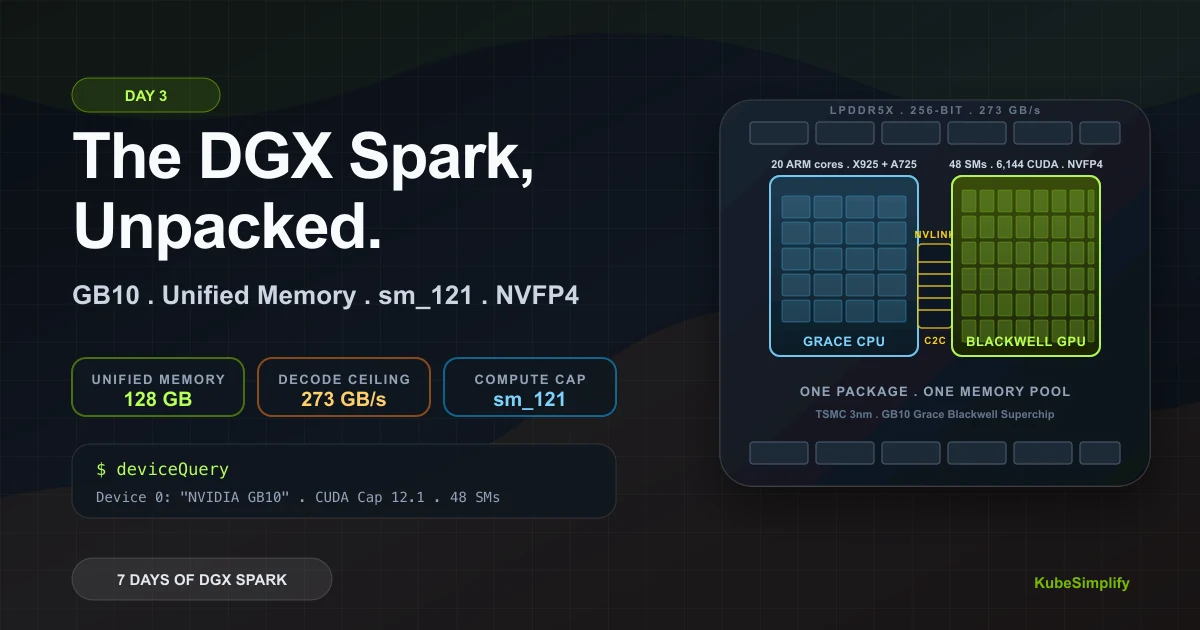
Day 3: The DGX Spark Unpacked. GB10, Unified Memory, sm_121, and the One Reason This Hardware Exists
A practical teardown of NVIDIA DGX Spark's GB10 Grace Blackwell Superchip, unified memory, sm_121, NVFP4 tensor cores, memory reporting, and decode limits.
Wandler: Local OpenAI-Compatible Inference With Transformers.js and WebGPU
A practical Wandler deep dive with a local M1 Max WebGPU demo, real latency numbers, architecture diagrams, and getting-started commands.

mlxcel: A Rust-Native Inference Engine for Apple Silicon, Tested on My M1 Max
Day-one deep dive into mlxcel v0.1.0, a Rust-native MLX inference engine. Real M1 Max benchmarks vs mlx-lm and Ollama on Llama 3.2 3B and Qwen 2.5 7B, with architecture diagrams and an honest take on TurboQuant.
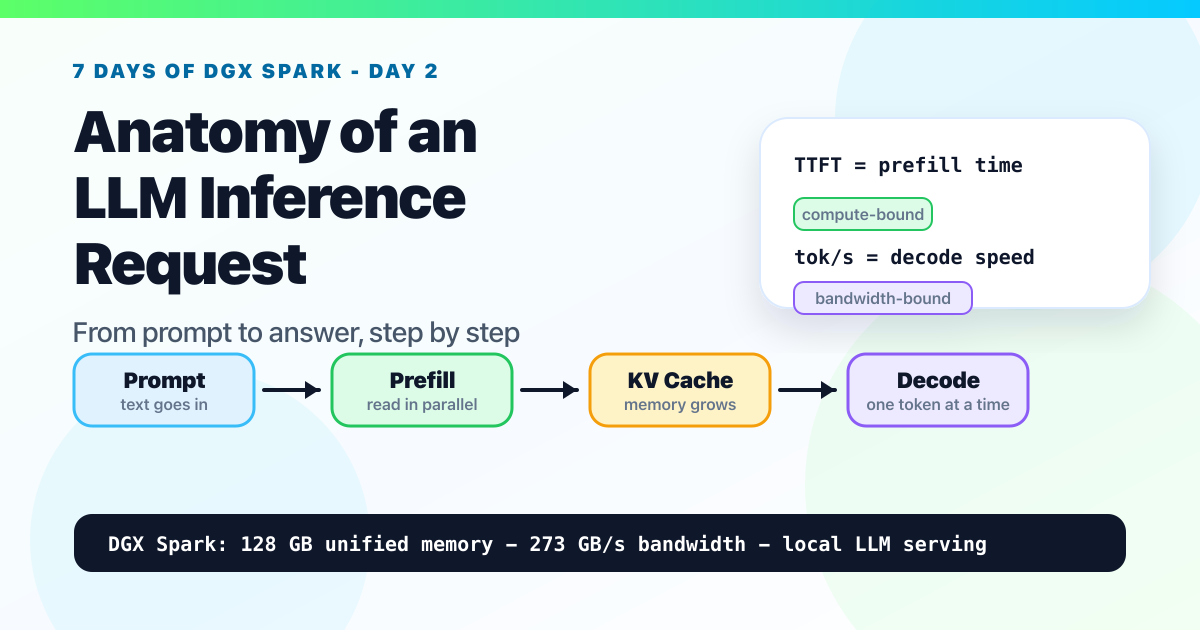
Day 2: Anatomy of an LLM Inference Request. From Prompt to Answer, Step by Step
A beginner-friendly walkthrough of tokenization, prefill, KV cache, decode, batching, TTFT, and why memory bandwidth shapes local LLM performance on NVIDIA DGX Spark.

Day 1: The Local LLM Revolution. Why Your Desk Just Became the New Datacenter
Why local LLMs are becoming practical in 2026, what changed across open weights, hardware, and inference software, and why DGX Spark makes the desk feel like a small AI lab.