Topic Hub
AI & ML on Cloud Native
Running AI/ML workloads on Kubernetes and modern infrastructure.
GPU scheduling, model serving, Kubeflow, LLMs on Kubernetes, NVIDIA NVCF, and the rapidly evolving AI infrastructure landscape.
Start here

NVCF Is Now Open Source: Inside NVIDIA's GPU Function Platform
NVIDIA just open-sourced the full NVCF platform under Apache 2.0. Not a thin SDK, not a client library. The actual control plane, invocation plane,…


K8sGPT Tutorial - When Kubernetes Meets AI
In this blog we’ll explore k8sGPT, a powerful tool that brings the capabilities of AI to change the way you manage Kubernetes.


Kubeflow: Machine Learning on Kubernetes - Part 1
Developing and deploying machine learning systems could be a pain with multiple things you need to manage. In this article, I introduce you and help you…


"SSH Into Your DGX Spark From Anywhere in the World Using Tailscale
Learn how to set up Tailscale on your NVIDIA DGX Spark for secure SSH access from anywhere in the world.
More on AI & ML on Cloud Native
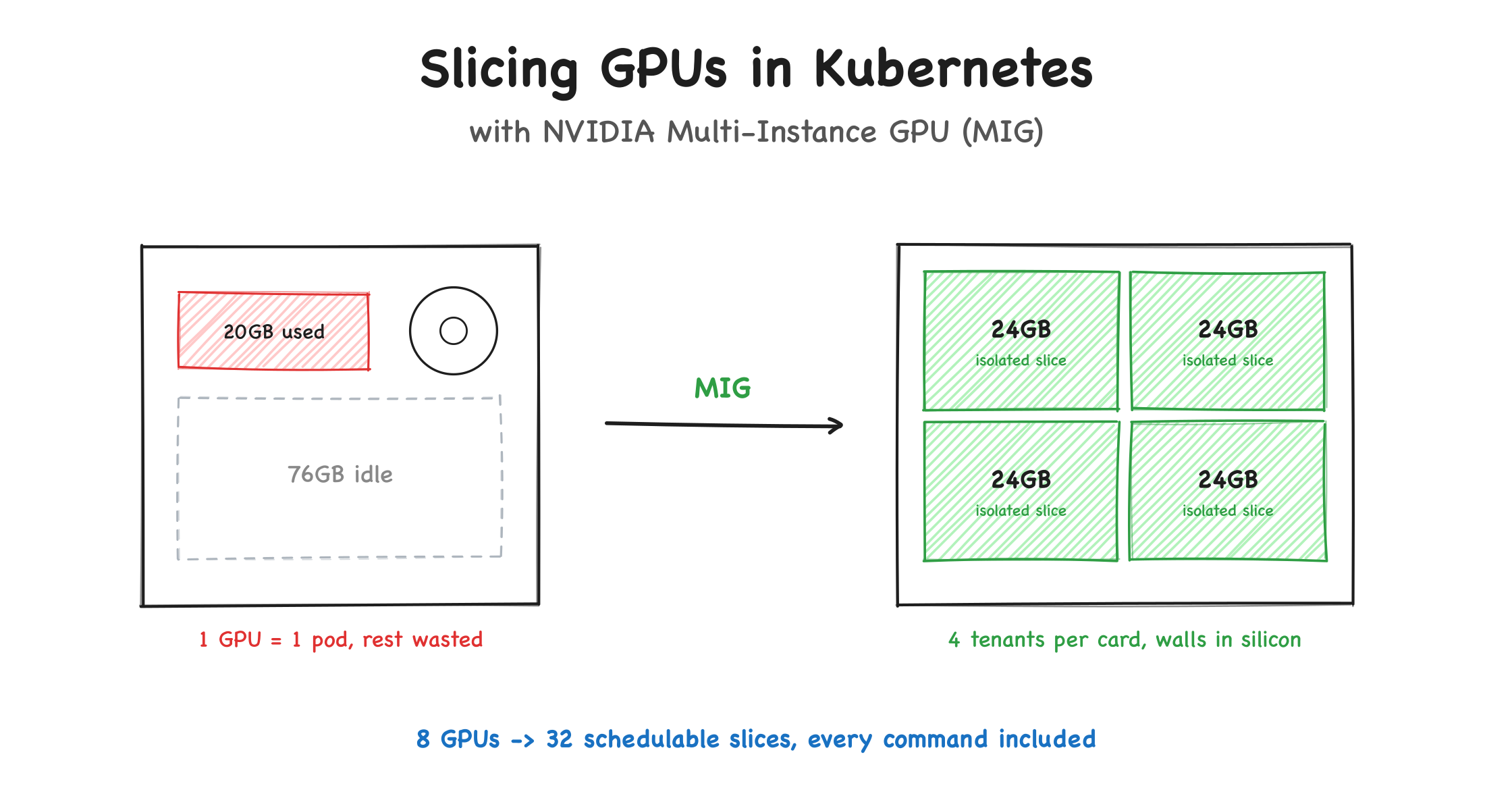
Slicing GPUs in Kubernetes with NVIDIA Multi-Instance GPU (MIG)
GPU sharing in Kubernetes explained: time-slicing vs MPS vs MIG, every nvidia-smi command to enable and disable MIG on one GPU or eight, GPU Operator automation, pitfalls, and DCGM monitoring.


Day 5: Local LLM Inference Engines, Wrappers, and What to Pick
A beginner-friendly guide to local LLM inference, with the same Qwen model tested through Ollama, llama.cpp, Docker Model Runner, vLLM, SGLang, and TensorRT-LLM on NVIDIA DGX Spark.
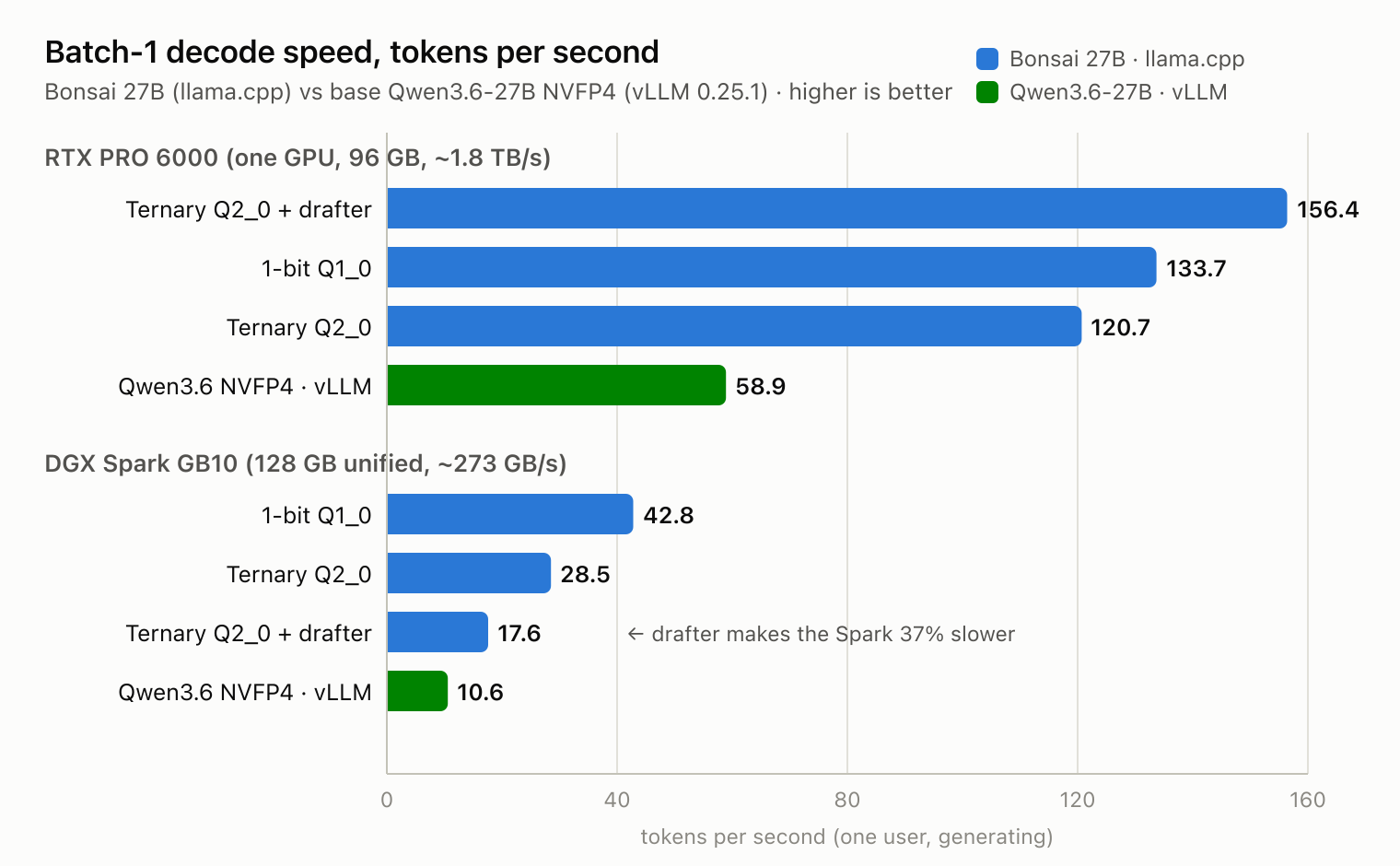
Bonsai 27B on RTX PRO 6000 vs DGX Spark: what actually works
Real Bonsai 27B benchmarks on an RTX PRO 6000 and a DGX Spark, including the supported llama.cpp setup, ternary vs 1-bit results, and speculative decoding.

Day 4: Quantization Demystified. BF16, FP8, NVFP4, MXFP4, INT4, GGUF, and Why It All Matters
A practical, beginner-friendly guide to BF16, FP8, NVFP4, MXFP4, INT4, and GGUF Q4_K_M on NVIDIA DGX Spark. Bytes per parameter, quality vs size, and which format to pick when.
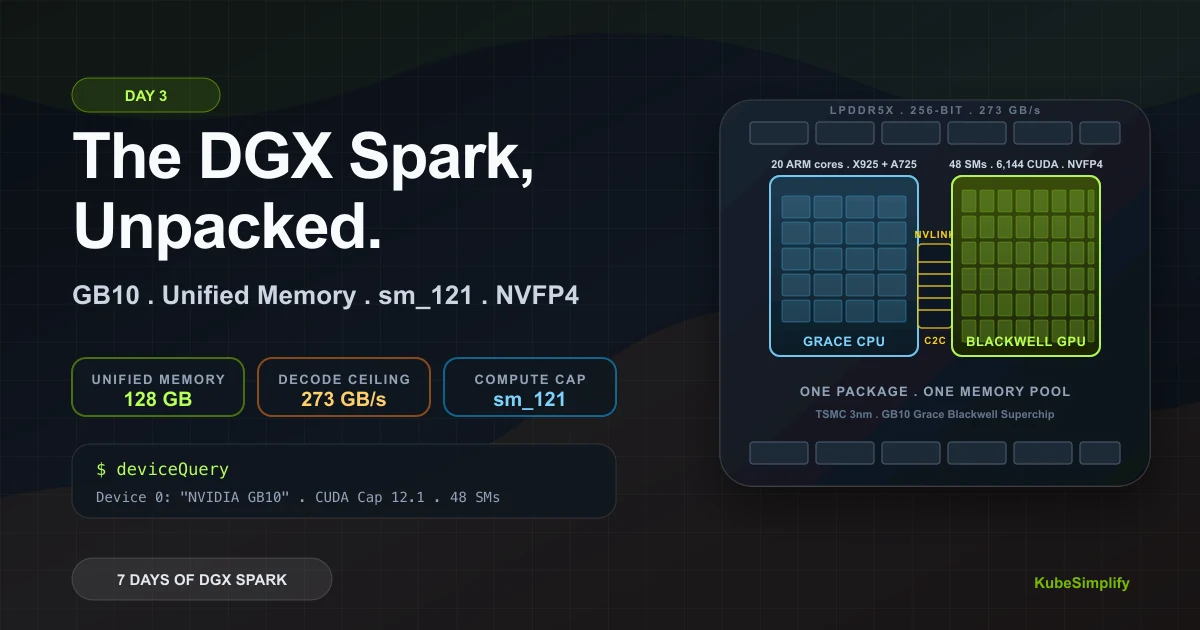
Day 3: The DGX Spark Unpacked. GB10, Unified Memory, sm_121, and the One Reason This Hardware Exists
A practical teardown of NVIDIA DGX Spark's GB10 Grace Blackwell Superchip, unified memory, sm_121, NVFP4 tensor cores, memory reporting, and decode limits.

mlxcel: A Rust-Native Inference Engine for Apple Silicon, Tested on My M1 Max
Day-one deep dive into mlxcel v0.1.0, a Rust-native MLX inference engine. Real M1 Max benchmarks vs mlx-lm and Ollama on Llama 3.2 3B and Qwen 2.5 7B, with architecture diagrams and an honest take on TurboQuant.
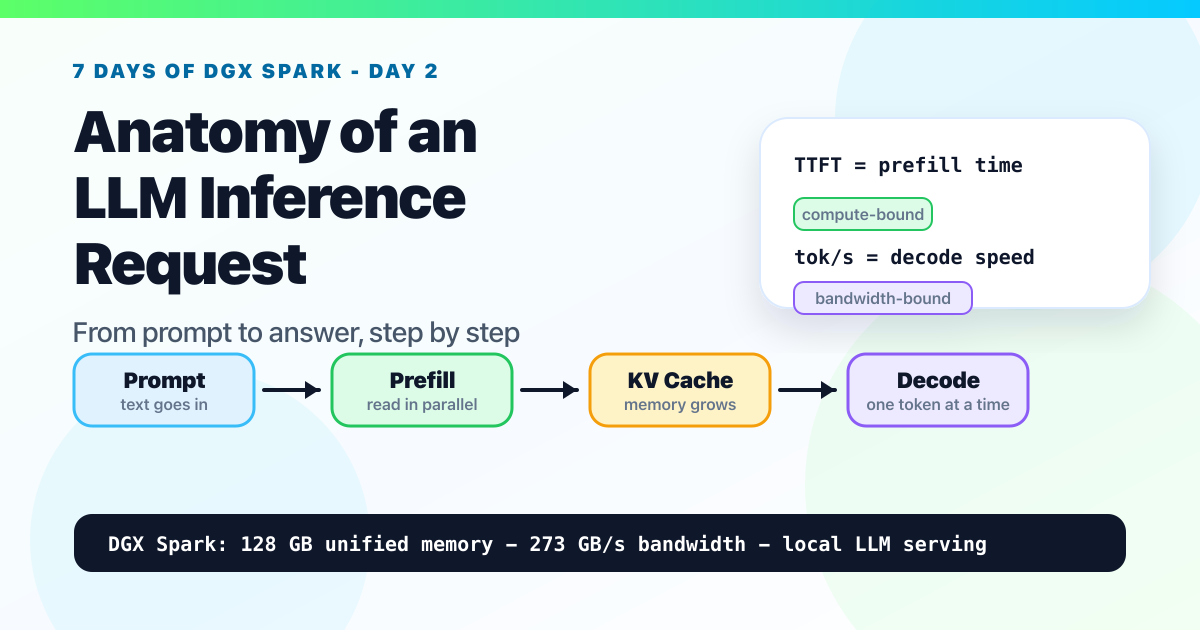
Day 2: Anatomy of an LLM Inference Request. From Prompt to Answer, Step by Step
A beginner-friendly walkthrough of tokenization, prefill, KV cache, decode, batching, TTFT, and why memory bandwidth shapes local LLM performance on NVIDIA DGX Spark.

Day 1: The Local LLM Revolution. Why Your Desk Just Became the New Datacenter
Why local LLMs are becoming practical in 2026, what changed across open weights, hardware, and inference software, and why DGX Spark makes the desk feel like a small AI lab.

Day 6: Run an LLM on Your Laptop - With Docker
"Pull AI models from Docker Hub, run them locally with GPU acceleration, and build an AI-powered app


What Claude Code's Leaked Source Actually Teaches Us About Building AI Agents
512K lines of TypeScript, verified against actual source. The engineering patterns in Claude Code's leaked codebase that most coverage got wrong.
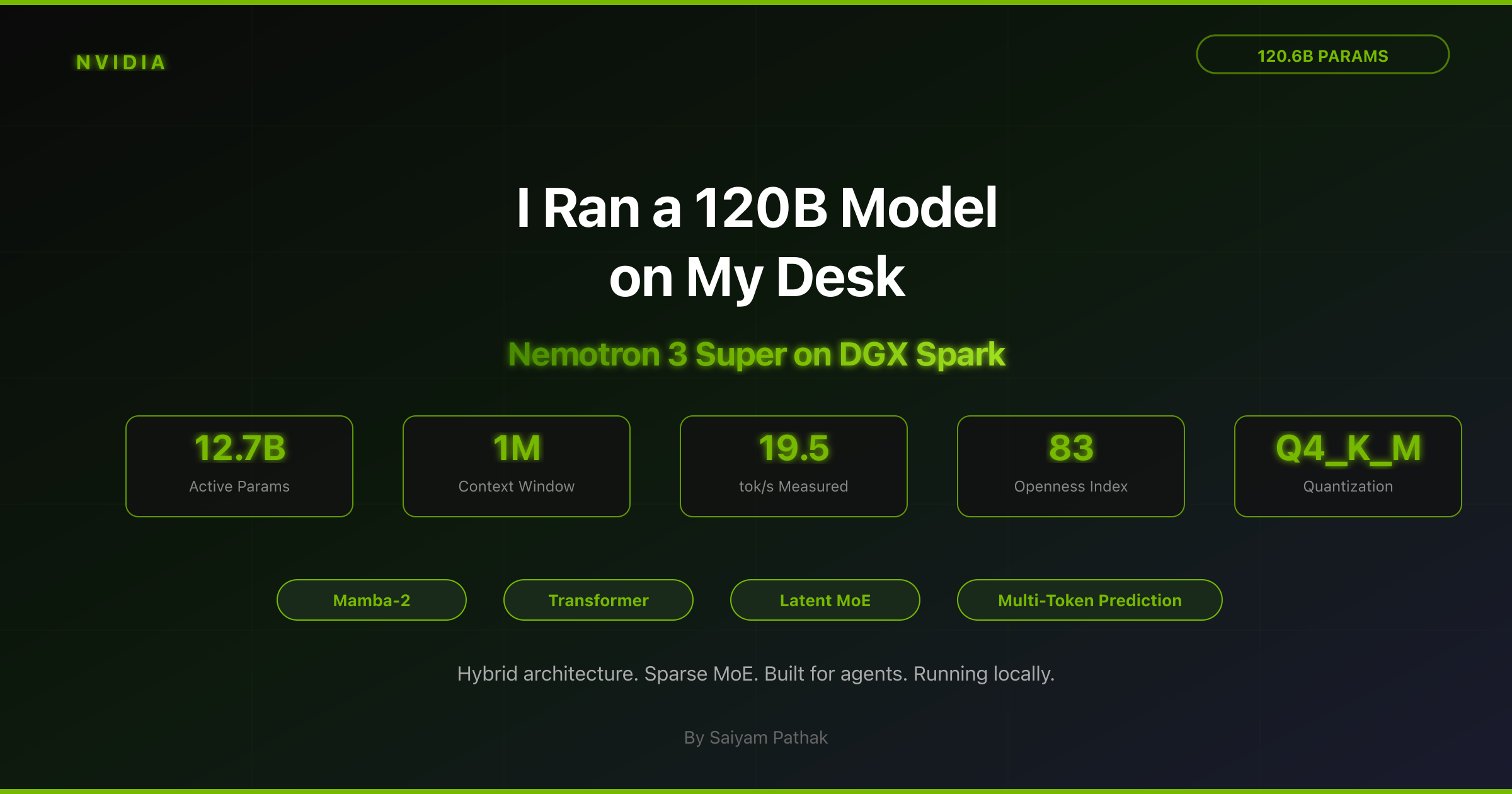
Here's What I Learned About Nemotron 3 Super -I Ran a 120B Parameter Model on Nvidia DGX Spark
Understand everything about Nvidia DGX spark along with hands on and benchmarks.

Ditch the Overheating Laptop: Supercharge Your Docker Workflow with Docker Offload
Running multiple Docker containers can slow down your laptop and drain your battery. In this blog, we explore Docker Offload — a game-changing feature